|
存在竞争风险的情况下,Kaplan-Meier的方法是不准确的,因为我们不能假定如果随访时间足够长,受试者将会发生感兴趣的事件。累积发生率(CIF)是给定事件发生的子分布,被广泛应用于竞争风险分析。 Fine和Gray(1999)提出的分布的比例风险模型旨在拟合感兴趣事件的累积发生率。关于Fine & Gray 模型,可以参考文献:“A Proportional Hazards Model for the Subdistribution of a Competing Risk. Jason P. Fine and Robert J. Gray,Journal of the American Statistical AssociationVol. 94, No. 446 (Jun., 1999), pp. 496-509”. 研究治疗方案A和白血病复发的关系,如果患者在去医院复查的路上出车祸意外死亡了,就观察不到白血病复发了,也就是说“车祸死亡” 和“复发”存在竞争。这样的现象在医学研究中,非常常见! 在分析某事件发生时间时,如果该事件被其他事件阻碍,即存在竞争风险。 例如这篇喝咖啡与低死亡风险的研究。Association of Coffee Consumption With Total and Cause-Specific Mortality Among Nonwhite Populations. Ann Intern Med, 2017. SCI IF=17.1 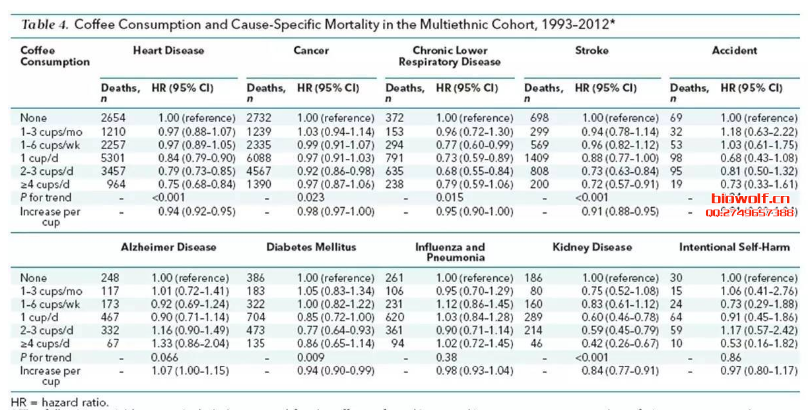 表4的结果表明排前10位的死因有心脏病、癌症、慢性下呼吸道疾病、卒中等。根据趋势性检验(P for trend)的结果,发现跟喝咖啡反向关系显著的是心脏病、癌症、慢性下呼吸道疾病、卒中、糖尿病和肾脏病原因导致的死亡。问题是死亡原因存在竞争关系,因为突发卒中死亡的人不太可能因为自杀再死一回。 本研究的作者在统计方法中写了:考虑到竞争风险后分析咖啡和不同原因死亡的关系,其中不同的死亡原因被认为是不同的事件。 分析结果表明没有发现考虑到死因之间的竞争风险影响结果(P=0.92)。相当于敏感性分析:做和不做竞争风险,得出的两套结果对比一下,如果差异不大表明结果稳定。 如何实现竞争风险模型分析呢?SEER数据库又如何做竞争风险模型呢? 首选我们需要从SEER数据库下载癌症临床数据,一般可以使用perl提取,或者直接下载SEER*Stat软件,在进行数据下载,当然下载数据之后,我们需要对数据进行清洗,常见的操作包括删除数据未知的条目,如果需要也可以把SEER多原发的数据提取出来,发生多原发的条目给删除。 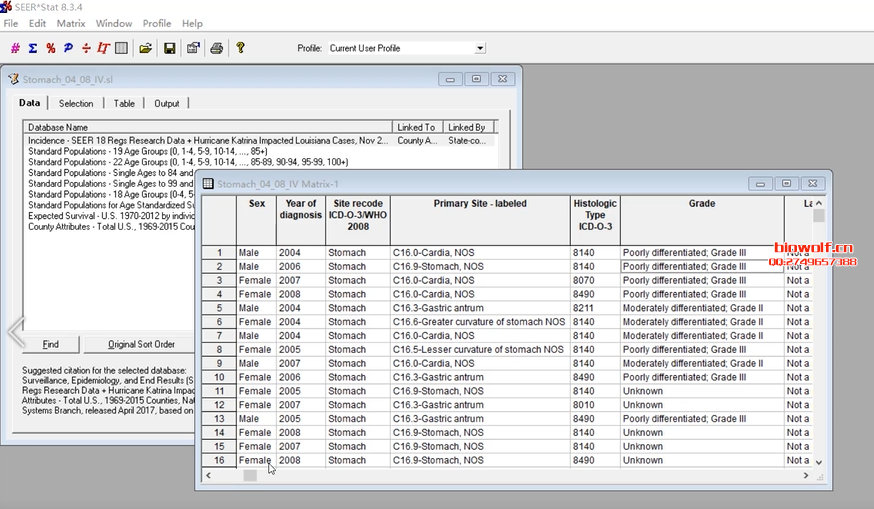 然后找到我们常见的SEER字段,标注出来 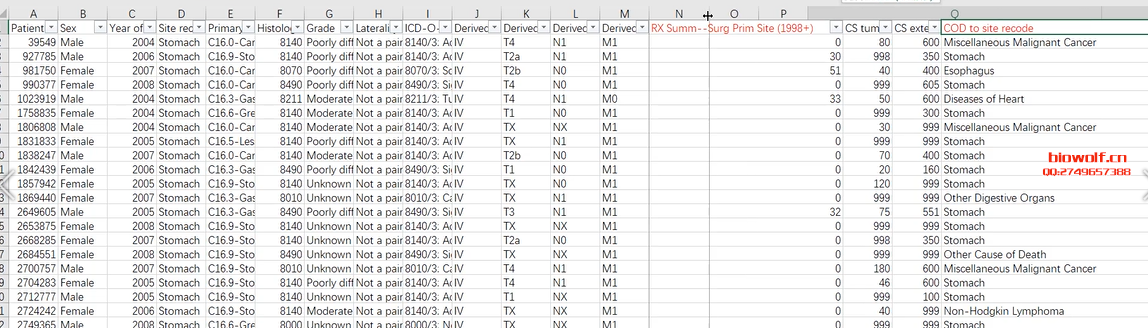 找到死亡原因和生存状态两列,通过这两列数据,我们把死亡原因分为三类——生存,死于癌症,非癌症死亡,这样我们就可以做竞争风险模型。 接下来用R包做曲线绘制: 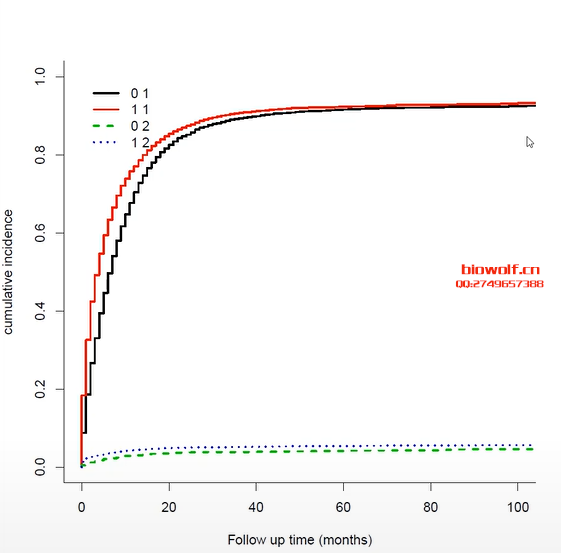 这样的话,我们就把SEER数据库的竞争风险模型构建出来了,如果需要详细学习相关操作,可以购买生信课堂的课程: SEER数据库竞争风险模型 加入微信公众号,获取更多资讯 
责任编辑:伏泽 作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载! |




