|
肿瘤临床利用Nomogram构建列线图文献解读 A nomogram for predicting 1-year survival in patients with advanced gastric cancer in the palliative chemotherapy setting was developed using clinicopathological data from 949 patients with unresectable or metastatic gastric cancer who had received first-line doublet cytotoxic chemotherapy from 2001 to 2006 at the National Cancer Center, Korea (Baseline Nomogram). For 836 patients whose initial response to chemotherapy is known, another nomogram (ChemoResponse-based Nomogram) was constructed using the response to chemotherapy as additional variable. Nomogram performance in terms of discrimination and calibration ability was evaluated using the C statistic and Hosmer–Lemeshow-type χ2 statistics. 方法: 利用2001年至2006年在韩国国家癌症中心接受一线双联细胞毒化疗的949例不可切除或转移性胃癌患者的临床病理数据,建立了一种预测晚期胃癌患者姑息化疗环境下1年生存率的列线图(Baseline Nomogram)。对836例化疗初治反应已知的患者,以化疗反应为附加变量,构建了另一种列线图(基于化疗反应的列线图)。利用C统计量和Hosmer–Lemeshow型χ2统计量,评价了列线图在鉴别和校准能力方面的表现。 本推文文献下载:关注公众号:biowolf_cn,回复“列线图”,即可下载原文  当然如果我们没有这么优秀的数据,怎么办?SEER肿瘤临床数据库可以帮到你,纯生信挖掘SEER数据库,也可以利用Nomogram构建列线图模型,生信自学网录制了一个入门的seer列线图课程: 《SEER列线图绘制入门》 文章题目是:使用Nomograms预测接受联合细胞毒性化疗作为一线治疗的不可切除或转移性胃癌患者的生存率。研究的对象是949例化疗的胃癌患者,观察终点是1年后患者的生存情况。使用的方法是Cox生存分析,预测模型的展示方法是nomogram列线图。 图一:Flowchart 流程图 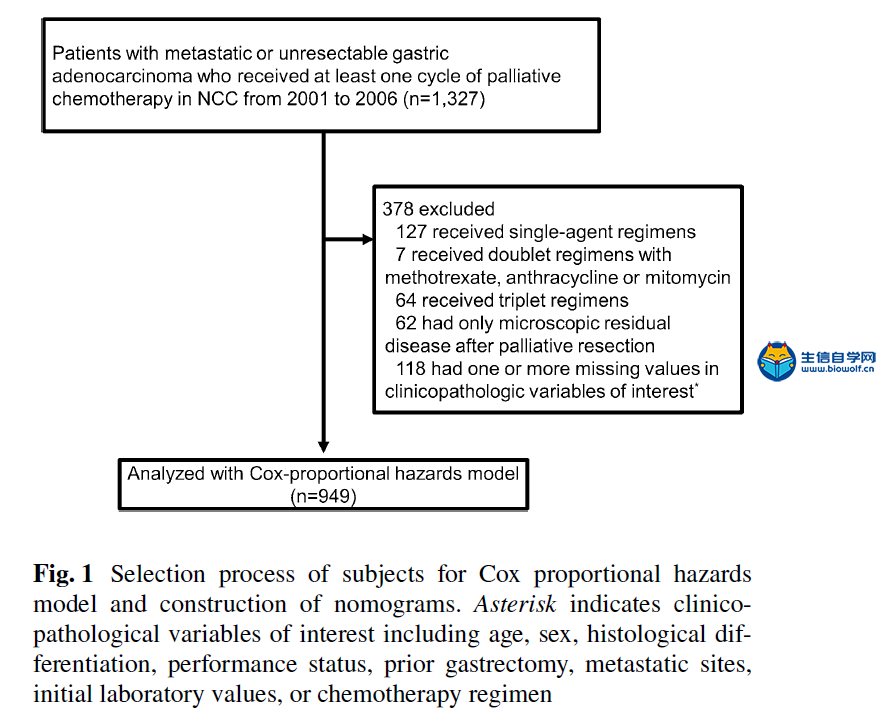 我们还是从图表的角度剖析这篇文章。第一个图是大家最熟悉的流程图,流程图的重要性就不在强调了,几乎每篇文章必备。文章收集了2001年到2006年共计1327例接受化疗的胃癌患者。排除328人,剩余949人进入Cox模型。 表一:研究人群描述 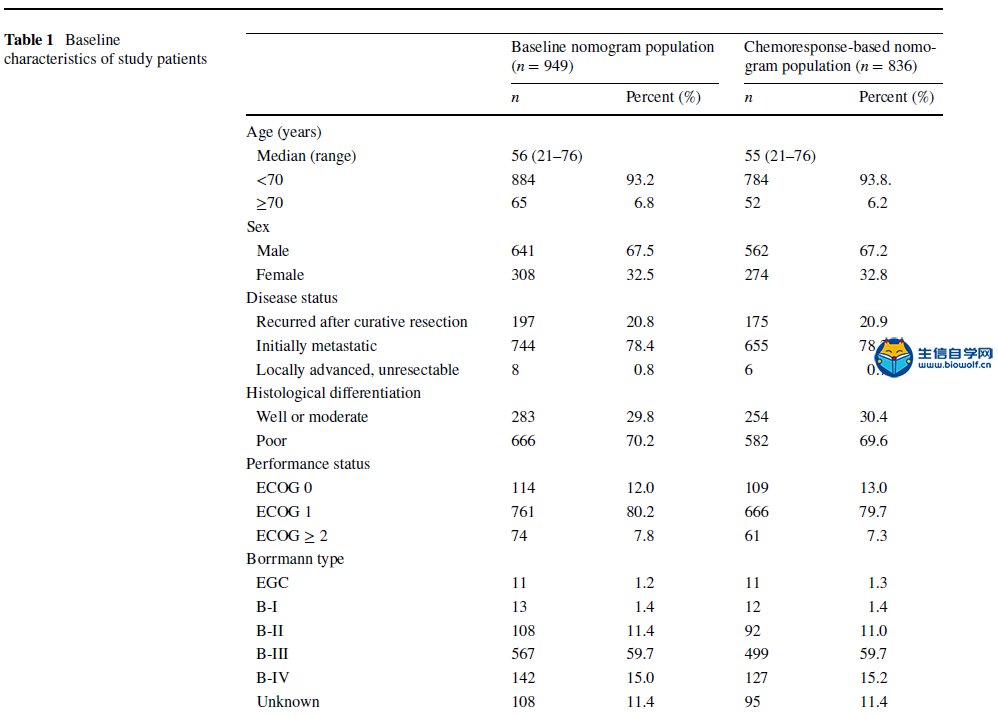 如果说图一看不出什么端倪,那么从表一开始,这篇文章的独特之处就可以显现出来了:作者把人群分成了2组,一组是基线列线图人群,一组是基于化疗反应列线图人群。 这是什么意思呢?作者整篇文章共做了2个预测模型,一个是基于患者化疗之前的危险因素进行预测,另一个则是化疗开始后9周观察到患者对化疗初期反应之后的因素进行预测。 换句话说,当一个胃癌患者来了之后,首先可以通过基线数据进行风险评估预测,决定是否进行接受联合细胞毒性化疗。患者化疗之后,可以通过初期化疗反应再次进行评估,决定是否继续化疗。两个模型结合为医生提供化疗决策的帮助。 其实这个时候作者的思路就已经显现出来了,这也是文章的核心亮点,可以猜想,作者下面的内容则是围绕2个模型进行书写,我们继续往下看。 表二:预测因子筛选 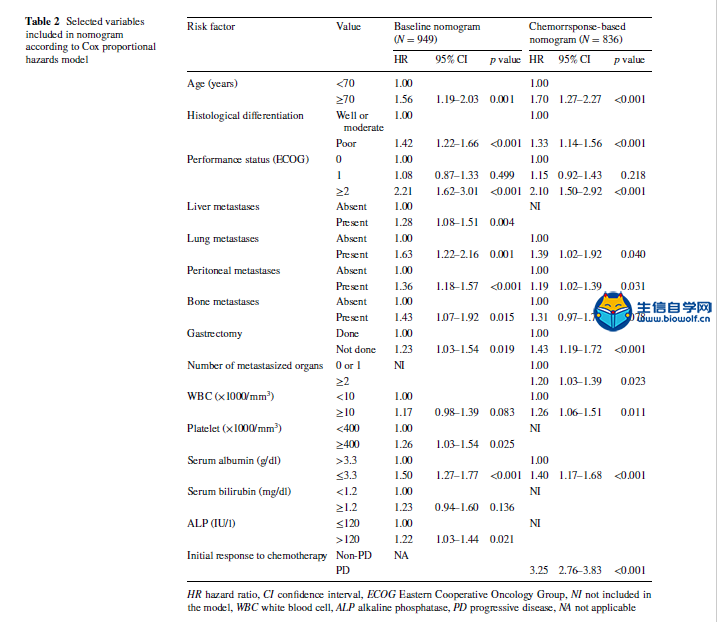 表二是文章的重要内容:纳入列线图的危险因素,这里展示了预测模型用到的变量,同时展示了每个危险因素的HR风险比。 预测模型的难点在于预测因子的筛选,很多同学都在苦恼用什么原则选择,这篇文章则描述的非常清楚,大家可以学习。简单概述一下:文章首先使用基础模型和年龄调整模型进行单因素分析,定义出来潜在的危险因素,然后使用前进、后退、逐步分析方法在多因素模型中筛选出了最佳模型。在使用这些方法的时候,一类错误α的取值为0.20,也就是p<0.2,这样的好处是降低样本量的影响。 同时,在这个表中最下面一列,展示出来2个模型的最大差异之处:化疗后9周之内的反应。基线nomogram中没有这个变量,基于化疗反应的nomogram则使用了这个变量。 图二:nomogram列线图 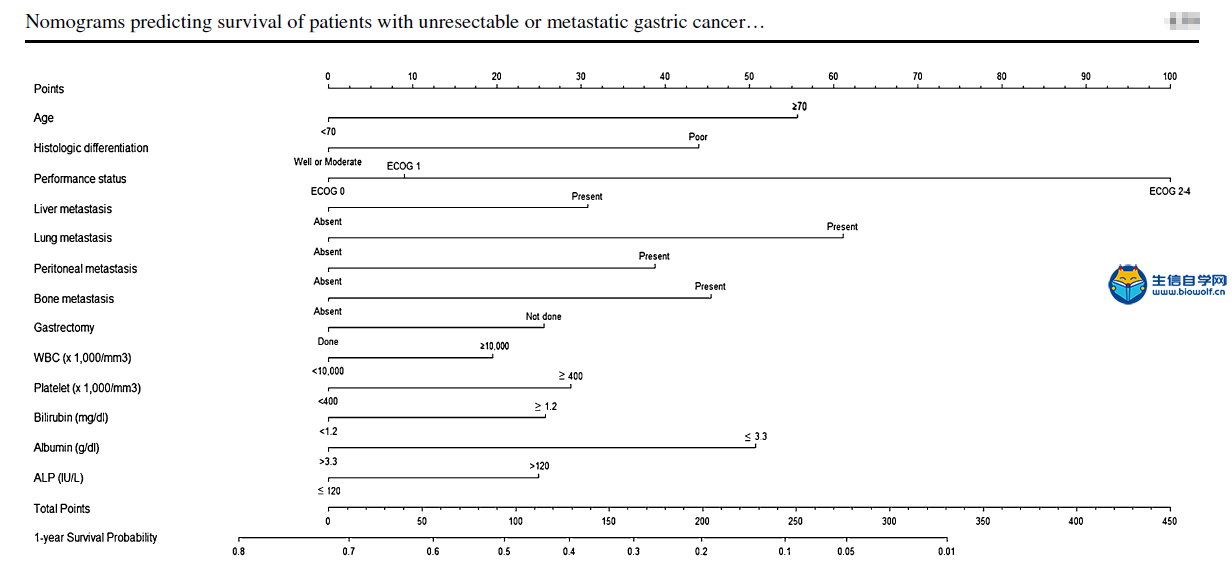 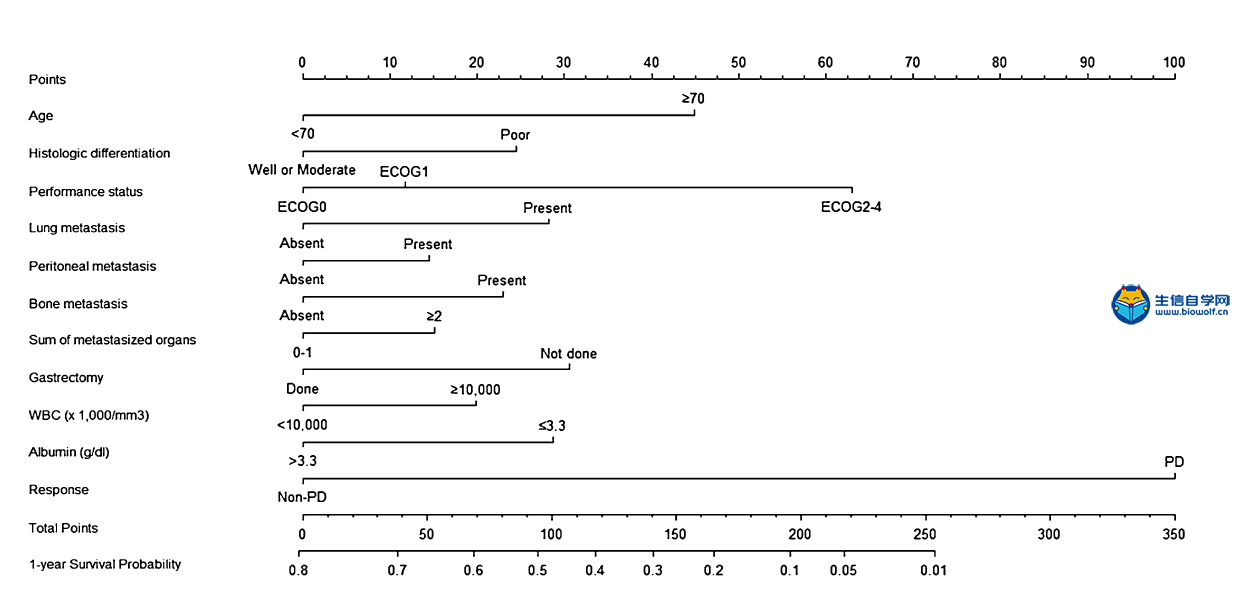 最后一步就是展示列线图了,有了前面表二的铺垫,图二分别展示了2个模型的nomogram,1个基于基线资料预测,1个基于化疗后初期反应预测,一切水到渠成。文章没有再放ROC曲线,直接列出了2个模型的C-index分别是0.656(95CI%,0.628-0.673)和0.718(95CI%,0.694-0.741) 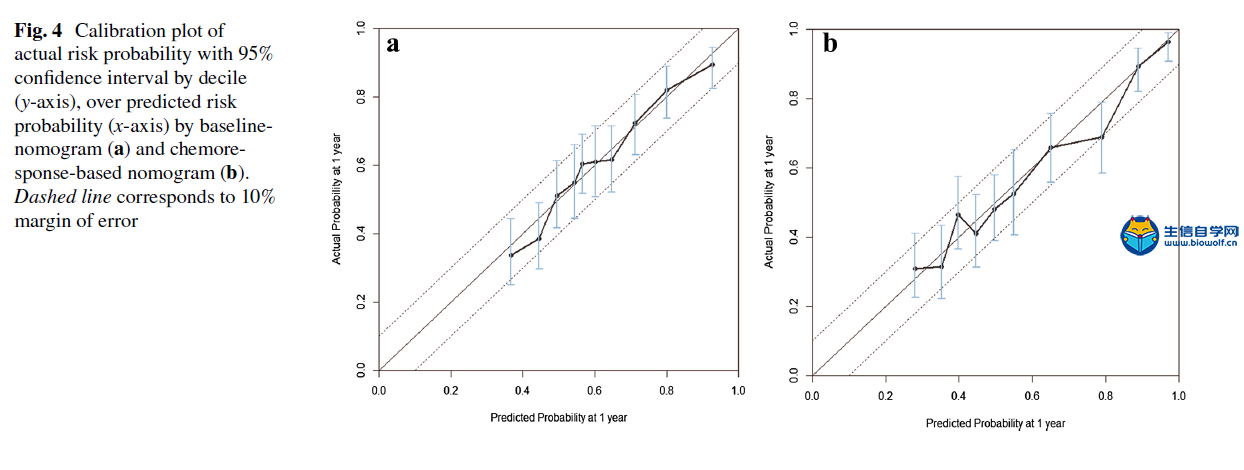 图四、表三:校准曲线和风险分层 最后的图和表作为文章的辅助材料,我一并放出来。一个是列线图的校准曲线,校准曲线是实际风险和预测风险的对比,曲线约接近对角线,说明预测效果越好。 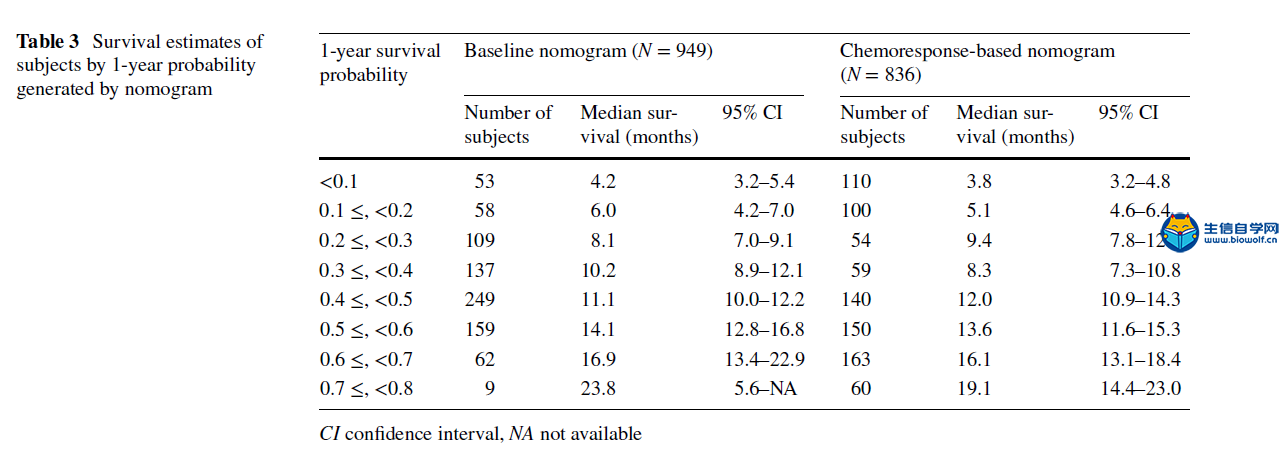 第二个图则是按照风险大小进行分层,分别展示了每组的人数和中为生存时间,从侧面说明了不同风险值患者的实际生存情况,让大家对生存时间有更直接的认识。 以上就是这篇文章的全部内容啦,我们简单整理一下思路:作者通过对医院现有化疗患者数据进行挖掘,建立了2个模型:一个是在化疗开始前进行预后评估,另一个是在化疗初期,通过化疗反应进行预后评估。2个模型是文章的最大亮点,nomogram作为载体展示了预测模型的结果,较为新颖。 当然如果我们没有这么优秀的数据,怎么办?SEER肿瘤临床数据库可以帮到你,纯生信挖掘SEER数据库,也可以利用Nomogram构建列线图模型,生信自学网录制了一个入门的seer列线图课程: 《SEER列线图绘制入门》 
责任编辑:伏泽 作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载! |




