|
TCGA数据库33种主要癌症的数据已经可以获取了,有学员就会说,TCGA数据库本来就提供下载啊,有什么稀奇的? 经过半年的下载与整理,33种的重要癌症的基本临床信息、完整临床信息、mRNA表达矩阵、lncRNA表达矩阵、miRNA表达矩阵,都已经统计完成,每位学员都可以获取,不用再苦逼的凌晨起来gdc下载数据,不用到处搜索如何提取临床数据,如何提取矩阵文件,如果你需要节省宝贵的时间做更加重要的研究,那么整理好的这些数据,可以直接用于后续的分析。 癌症数据: 1、基本临床数据 行名是样本代号,列名是临床信息(包含16列主要临床信息,一般的研究和临床统计是能够满足的),如图 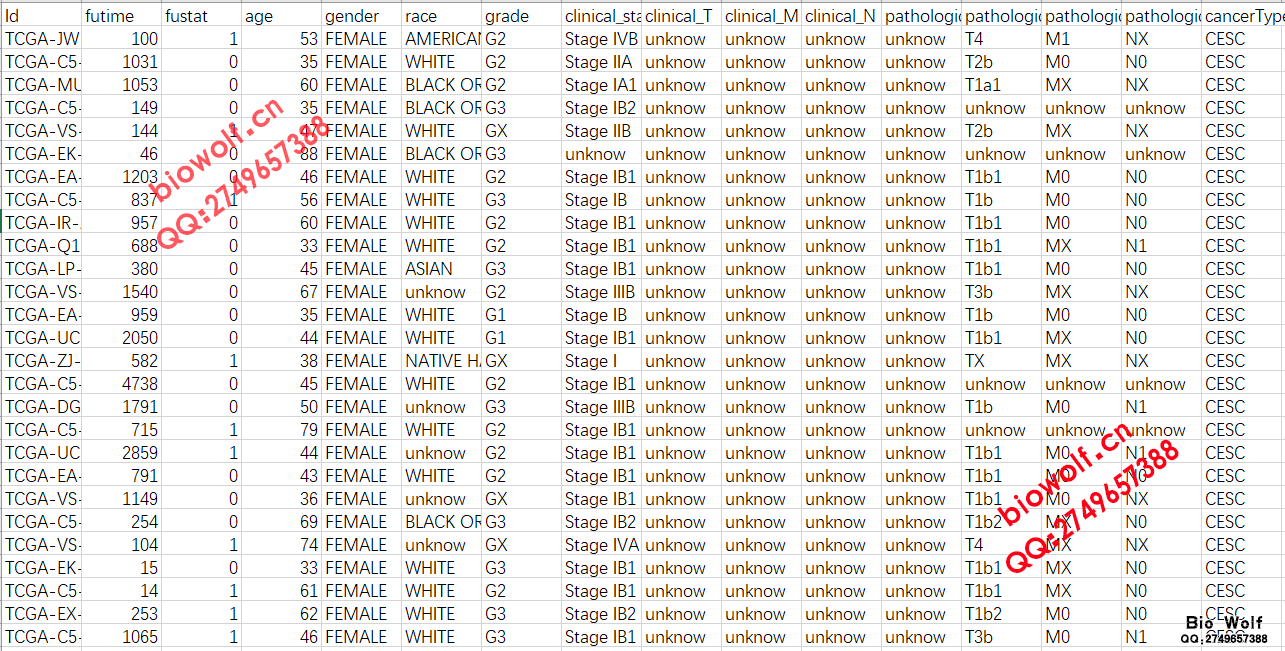 2、完整临床数据 行名是样本代号,列名是临床信息(包含150列左右,具体列数每个癌症样本不一样,包含全部的临床信息),如图 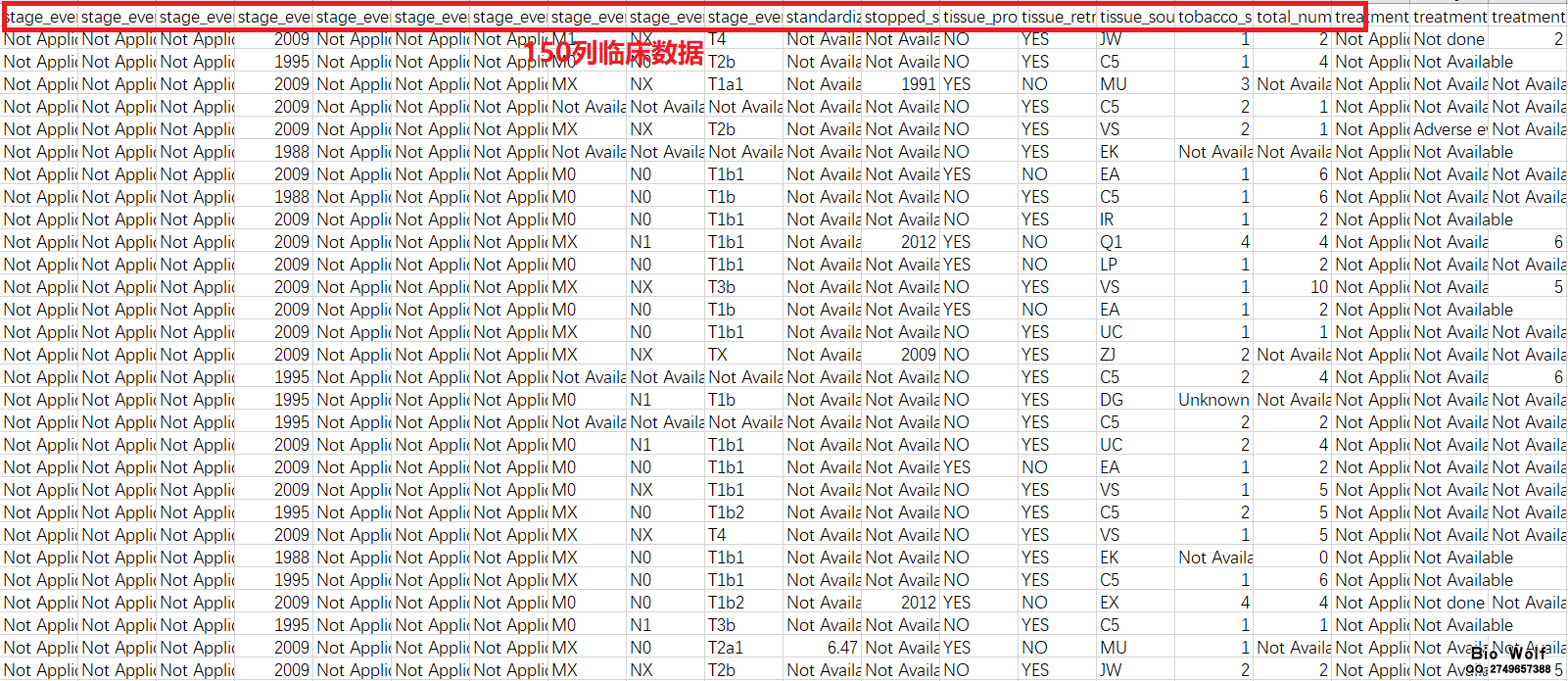 3、mRNA表达矩阵 行名是gene symbol,列名是样本代号,如图 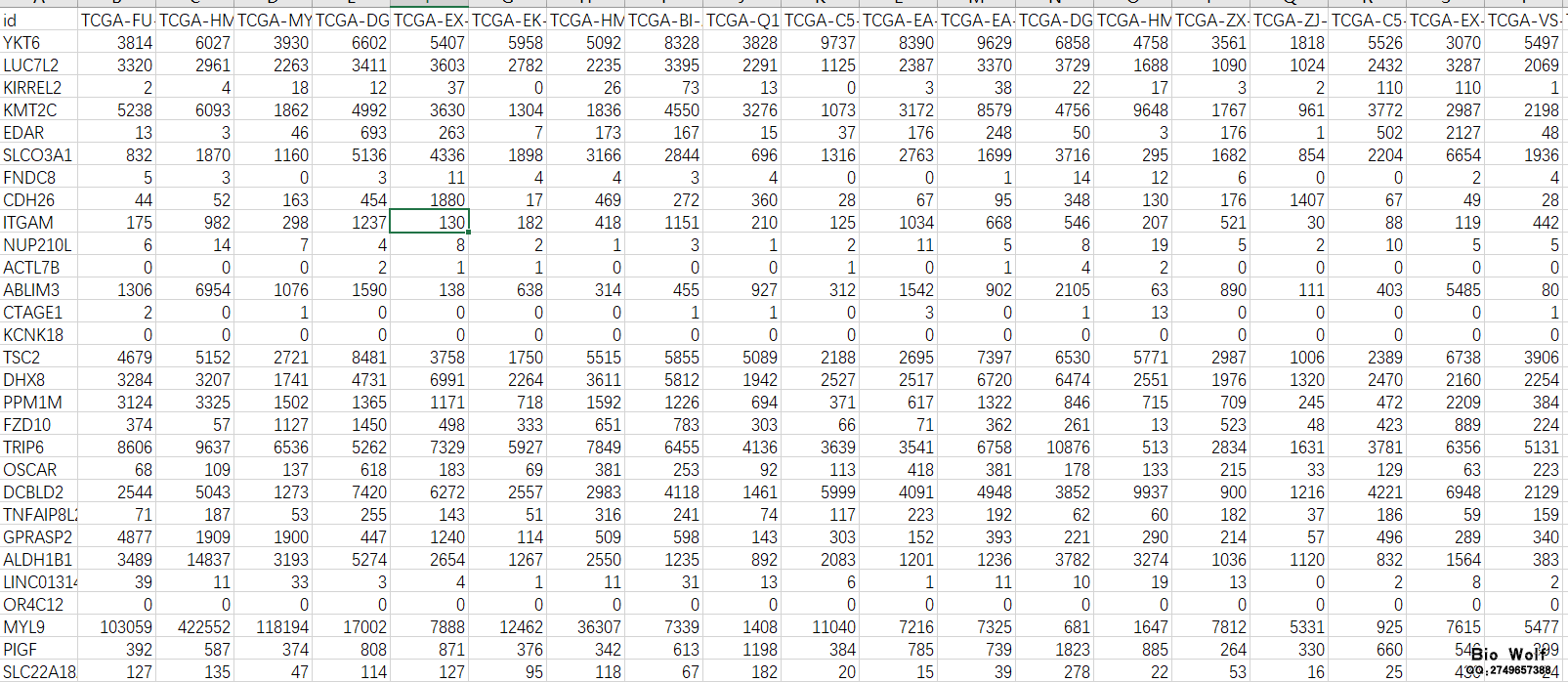 4、lncRNA表达矩阵 行名是lncRNA,列名是样本代号,如图 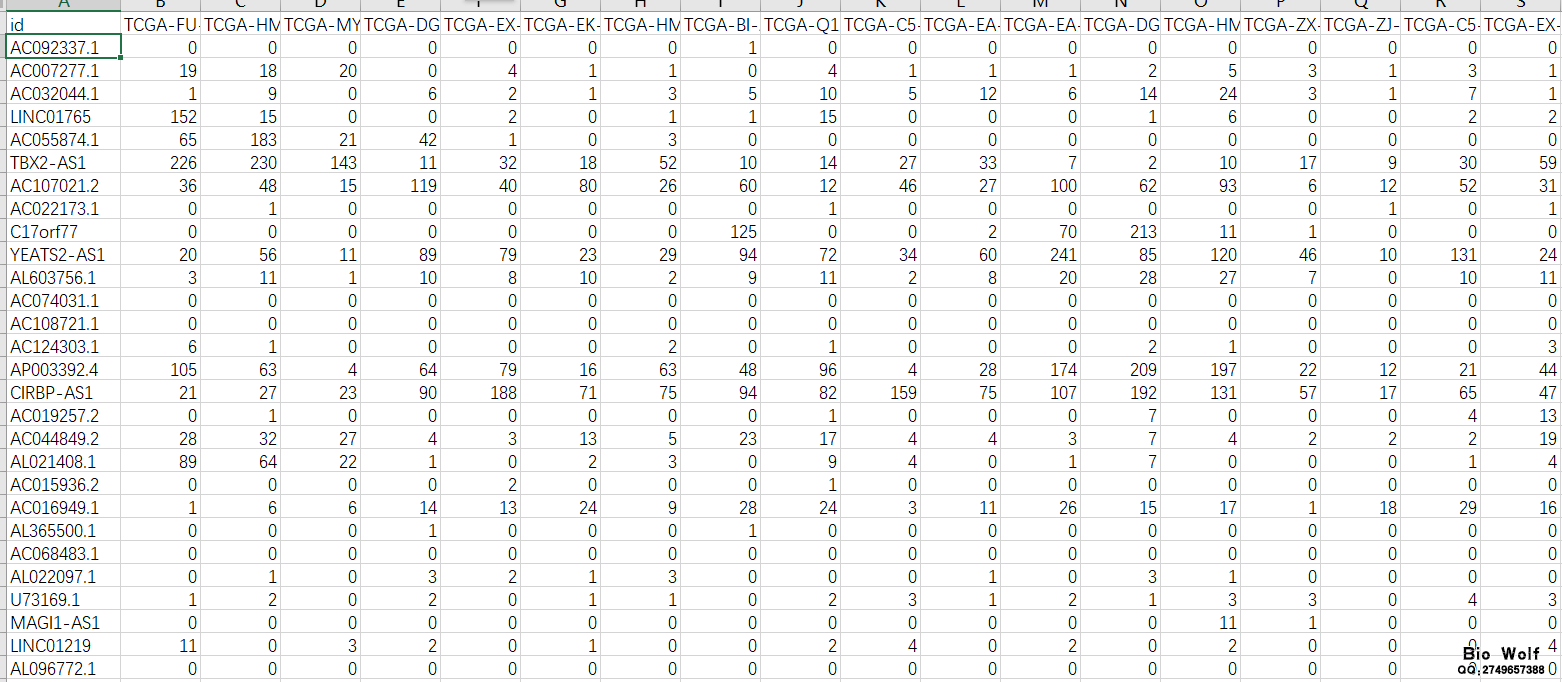 5、miRNA表达矩阵 行名是miRNA,列名是样本代号,如图 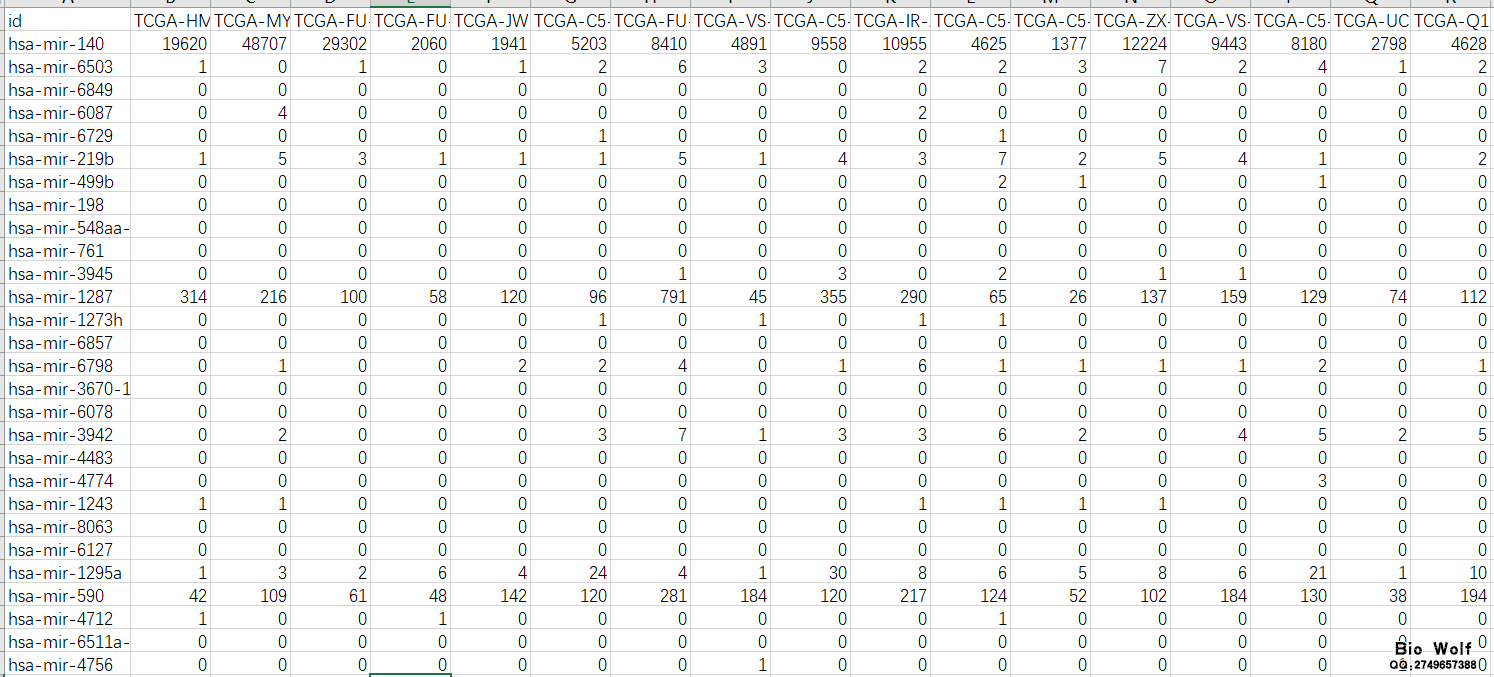 6、打包销售 包括基本临床数据、完整临床数据、mRNA表达矩阵、lncRNA表达矩阵、miRNA表达矩阵 购买方式: 1、加服务QQ:2749657388,联系客服,选择癌症类型,数据类型,确认价格。支持支付宝、微信付款;付款后百度网盘下载数据; 2、扫码付款,付款成功后加微信公众号,直接在输入框数据癌症类型、数据类型和付款金额,邮箱或者是QQ号,客服收到信息验证付款后,发送数据或者百度网盘下载地址。 癌症类型和数据类型参见下表: 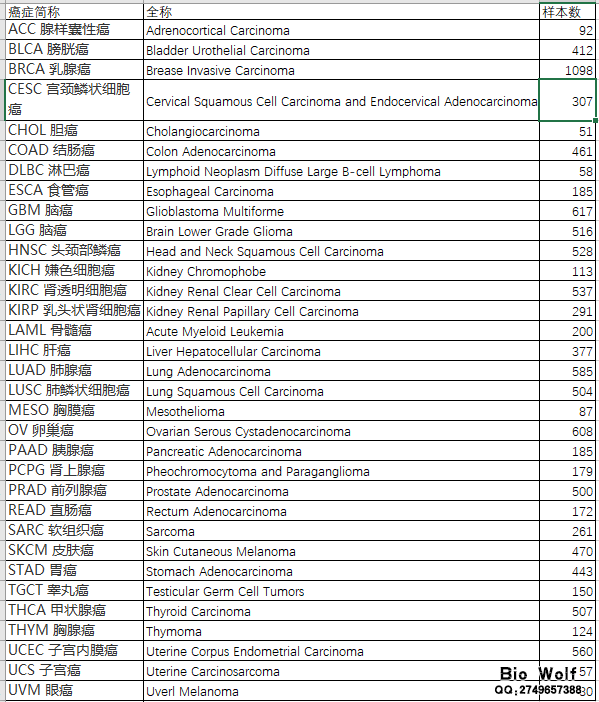 癌症类型: 1、ACC 腺样囊性癌;2、BLCA 膀胱癌;3、BRCA 乳腺癌;4、CESC 宫颈鳞状细胞癌;5、CHOL 胆癌;6、COAD 结肠癌;7、DLBC 淋巴癌;8、ESCA 食管癌;9、GBM 脑癌;10、LGG 脑癌;11、HNSC 头颈部鳞癌;12、KICH 嫌色细胞癌;13、KIRC 肾透明细胞癌;14、KIRP 乳头状肾细胞癌;15、LAML 骨髓癌;16、LIHC 肝癌;17、LUAD 肺腺癌;18、LUSC 肺鳞状细胞癌;19、MESO 胸膜癌;20、OV 卵巢癌;21、PAAD 胰腺癌;22、PCPG 肾上腺癌;23、PRAD 前列腺癌;24、READ 直肠癌;25、SARC 软组织癌;26、SKCM 皮肤癌;27、STAD 胃癌;28、TGCT 睾丸癌;29、THCA 甲状腺癌;30、THYM 胸腺癌;31、UCEC 子宫内膜癌;32、UCS 子宫癌;33、UVM 眼癌 正常的工作流程本来是这样的: 1、进入TCGA的官网,选择研究相关的癌症类型,下载Clinical临床、Transcriptome Profiling中的Gene Expression Quantification、miRNA Expression Quantification的Metadata、Manifest文件,下载TCGA数据库提供的gdc下载工具; 2、利用gdc工具,在本地CMD环境数据下载命令:gdc-client.exe download -m gdc_manifest.txt,下载临床原始数据、基因表达数据、miRNA表达数据,其中临床数据是.xml的网页文本文件,基因表达数据是每个样本一个压缩包,miRNA表达数据是每个样本一个压缩包;  3、以宫颈鳞状细胞癌CESC为例,临床数据下载下来是307个文件夹,每个文件夹里有一个.xml文件,保存着一个样本的临床数据,需要想办法把这307个文件夹的307个.xml文件提取到一个exl文件里面,提取的临床数据一般都只包含一部分信息,为了获得完整的临床数据,很多学员想尽办法也没能成功; 4、CESC的基因表达包括307个文件,每个文件里面是一个压缩包,每个压缩包保存了一个.txt文件,这个.txt文件就保存着一个样本的表达信息。需要把307个压缩包提到一个文件夹中,使用压缩软件,把307个压缩包解压,得到307个.txt文件,再用提取脚本,把基因的表达矩阵提取出来;  5、基因矩阵提取出来之后,会发现TCGA用的GENE ID是Ensembl ID,所以需要把Ensembl ID转换成symbol ID,这一步又难倒了不少学员,当然教程生信自学网也有,可以去学习,现在Ensembl官方下载Ensembl的数据库,对照Ensembl数据库和基因矩阵,用脚本检索替换,得到symbol ID的矩阵; 6、基因矩阵包含mRNA和lncRNA以及其他一些基因,需要把mRNA和lncRNA分离出来,利用脚本提取mRNA和lncRNA的矩阵; 7、CESC的miRNA表达数据包括307个文件夹,每个文件夹包括一个.txt文件,这个.txt文件就保存了一个样本的miRNA表达信息,需要把307个.txt文件提取到一个文件夹内,用脚本提取这307个文件的表达信息,保存在一个exl文件里面。  看到这样的流程,估计还没开始操作,很多学员就惊叹了。不用惊讶,这样的分析步骤已经是大神级别,普通学员可能在研究如何下载TCGA数据,就花费了半个月的时间,每天都在搜索如何下载临床数据,如何下载基因表达数据。下载下来之后,一看傻眼了,怎么都是这样的,还能不能给人好好继续研究了。 从此刻起,这一切的烦恼都过去了,你本应该话更多时间做研究的,而不是花太多精力研究如何下载和提取临床信息,矩阵文件,后续的差异分析,生存分析,Cox分析,共表达分析才是TCGA数据挖掘的核心。当基本临床信息、完整临床信息、mRNA表达矩阵、lncRNA表达矩阵、miRNA表达矩阵都可以直接获取,你节省的不只是时间,还有科研进度,一步领先,步步领先,GEO数据库研究的现状就是TCGA数据库的未来,这个是发展的必然。 
责任编辑:伏泽 作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载! |




