|
TCGA数据库现在是生信分析的热点,生信自学网开创了用生信方法解读TCGA数据的先河,给研究者提供了新的研究方案。
有很多学员仍然不是很了解,TCGA所有数据都有的样品ID是如何规范的,那么我们来看看TCGA后台是如何把庞大的数据文本化的?
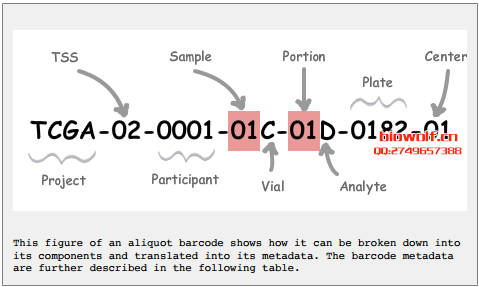
接触和分析过TCGA数据的朋友肯定会经常处理TCGA barcode的前15位(有时12位),实际从上图可以看出TCGA的barcode设计总共有28位之多。
每一个短横杠衔接的都是含不同意义的序列,如下图
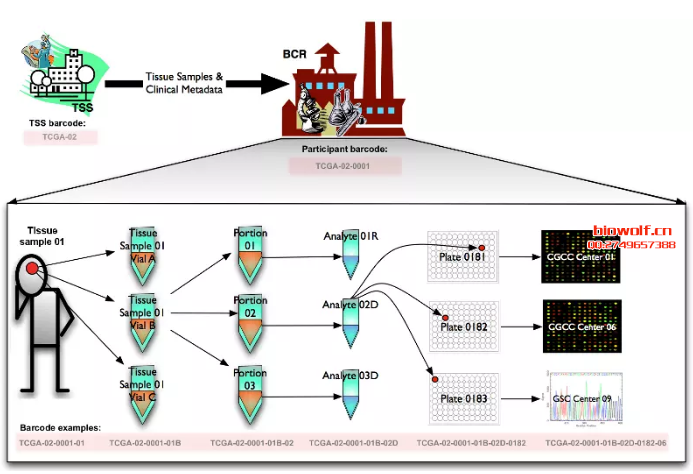
从TCGA数据库我们也找到了相关的说明文档:
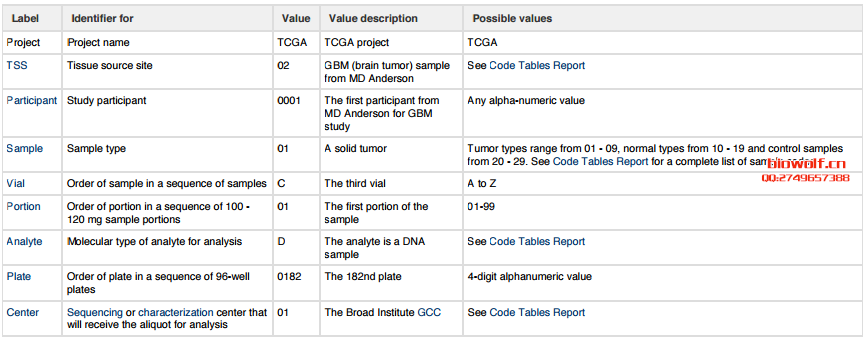
Barcode Types
Barcodes can also be visualized hierarchically, with TSS barcodes at the top of the tree and aliquot barcodes at the bottom. A parent barcode
prefixes any of its descendent barcodes, reflecting the derivation of one biospecimen type from another. For example, samples are collected from
a participant and so the corresponding sample barcodes contain the participant barcode from which they were derived.
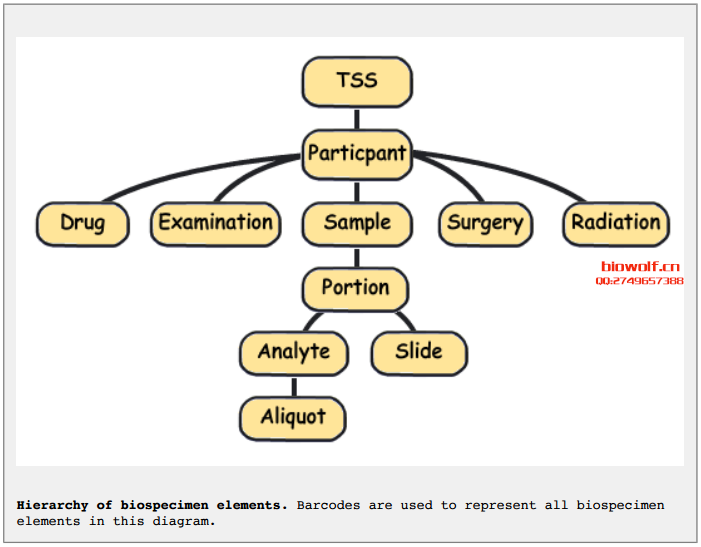
Using the aliquot barcode example from the figure in Reading Barcodes, the following table displays a possible set of related barcodes at each
level of the hierarchy:
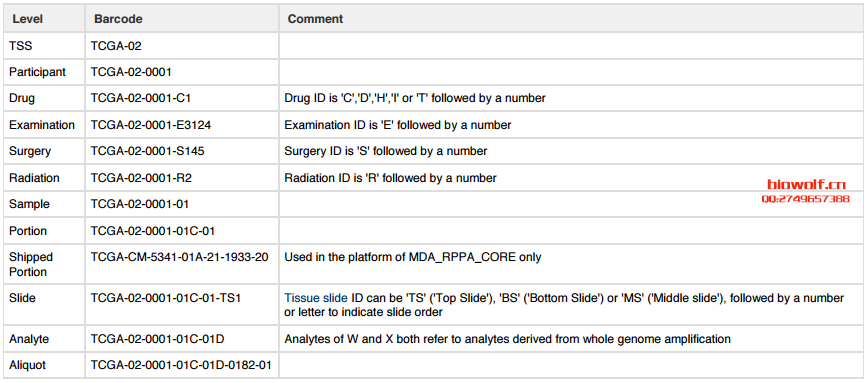
可以看到同一个样本(一个病人的某一个组织块),在实际的实验处理中是分了很多分析试样的,特别是plate部分。这也就导致在实际的分析中有可能会出现多个barcode对应同一个样本(即前15位是一致的)。
通过谷歌引擎找到Biostars上有人对这个问题加以讨论,我按照着提供的链接找到了Broad研究所进行barcode去重的策略:
主要内容如下:
In many instances there is more than one aliquot for a given combination of individual, platform, and data type. However, only one aliquot may be ingested into Firehose. Therefore, a set of precedence rules are applied to select the most scientifically advantageous one among them. Two filters are applied to achieve this aim: an Analyte Replicate Filter and a Sort Replicate Filter.
Analyte Replicate Filter
The following precedence rules are applied when the aliquots have differing analytes. For RNA aliquots, T analytes are dropped in preference to H and R analytes, since T is the inferior extraction protocol. If H and R are encountered, H is the chosen analyte. This is somewhat arbitrary and subject to change, since it is not clear at present whether H or R is the better protocol. If there are multiple aliquots associated with the chosen RNA analyte, the aliquot with the later plate number is chosen. For DNA aliquots, D analytes (native DNA) are preferred over G, W, or X (whole-genome amplified) analytes, unless the G, W, or X analyte sample has a higher plate number.
Sort Replicate Filter
The following precedence rules are applied when the analyte filter still produces more than one sample. The sort filter chooses the aliquot with the highest lexicographical sort value, to ensure that the barcode with the highest portion and/or plate number is selected when all other barcode fields are identical.
|
翻译成中文,大致有以下3点:
对于RNA分析, Analyte序列 H>R>T
对于DNA分析,Analyte序列中D>G,W,X
如果经常前面的过滤还重复样本,考虑portion和plate序列,选择更大的
另外,分析不使用福尔马林处理的样本(DNA与RNA分析数据失真,但这一点TCGA已经考虑了)

责任编辑:伏泽
作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载!
|




