一、查找和下载数据
从GEO搜索关键字“(gastric cancer)AND "Homo sapiens"[porgn:__txid9606]”,得到胃癌相关的表达谱数据。对这些数据进行过滤,过滤掉没有重复试验的样品。接下来,阅读文献,找出研究正常人和癌症病人,或者癌组织与正常组织的比较的数据。下载这些数据的表达矩阵或CEL文件,用于后续的分析。
表1用于分析的数据
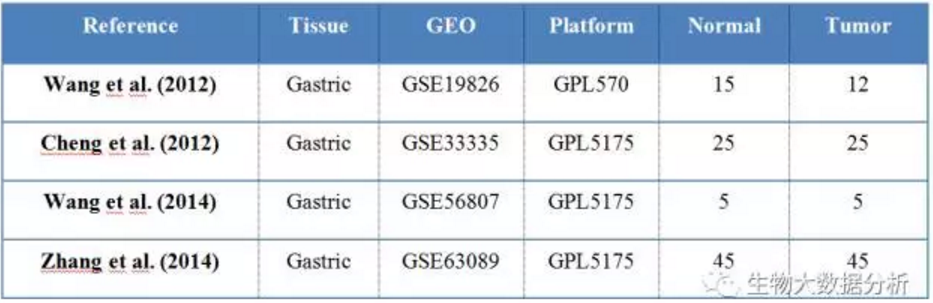
注:
Series 序列号
GEO GEO id
Platforms 芯片平台号
Normal 正常样品数目
Tumor 癌症样品数目
Reference 参考文献
二、数据处理
对于芯片表达值数据,直接从GEO下载数据,对于没有取log的值,进行取log处理。对于CEL文件,使用affy包读取CEL文件的表达量数据。在同一芯片内,如果一个基因有多个探针,取所有探针的平均值作为基因的表达值。
差异表达
对于每个实验的数据,我们使用limma进行芯片之间的标准化,差异表达分析(每个实验的limma分析结果保存在01_limma里面)。
每个实验数据做完limma分析之后,根据logFoldChange值对基因进行排序,然后进行Rank分析(adjust Pvalue<0.05,矫正方法为bonferroni矫正法)。Rank方法的零假设是每个基因在每个实验中随机排序,如果某个基因在所有实验中,都排在前面,那么它的p值越小,是差异基因可能性越大。
通过Rank分析,我们共找到960个差异基因,其中458个上调基因,502个下调基因。
使用pheatmap绘制最上调和最下调的20个基因做热图,得到差异基因的热图。从图中可以看出,上调的基因基本在所有实验中logFC>0,而下调的基因基本在所有的实验中logFC<0。
表2 差异基因列表
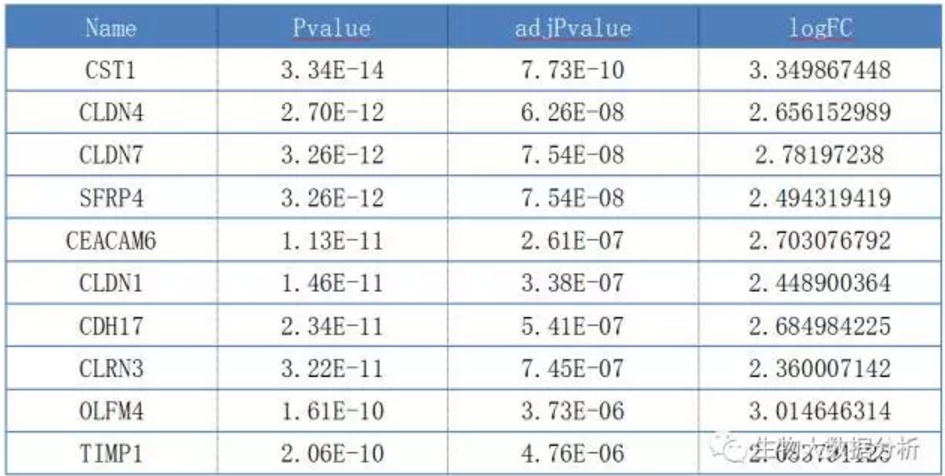
注:
Name gene symbol
logFC 每个实验差异logFC均值
Pvalue 统计学p值
adjPvalue 校正后的p值
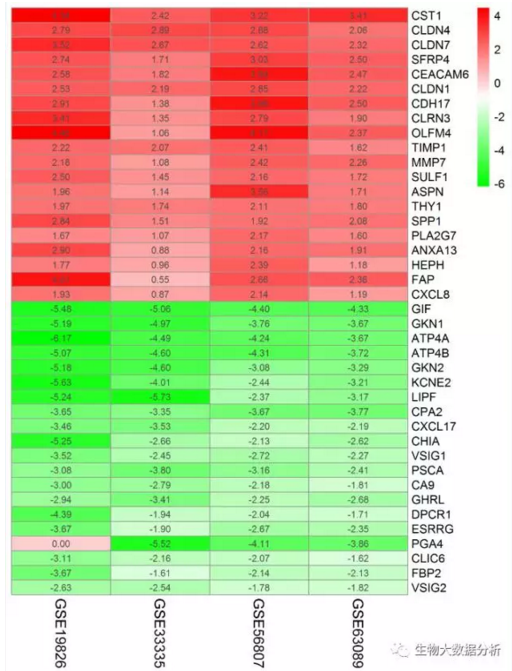
图1 logFC热图
横坐标是geo id,纵坐标是基因名,红色代表logFC>0,绿色代表logFC<0,方框里面的数值代表logFC值。
三、TCGA验证差异基因
从TCGA下载胃癌level3的RNA-seq数据,共xx个正常组织,xx个肿瘤组织。下载的数据是每个样品单个的FPKM文件,我们使用perl语言将所有的样品合并成一个矩阵,便于后续的分析。接下来,我们使用Wilcoxon tests非参数检验对GEO数据库得到差异基因进行验证。
通过TCGA验证,我们共找到749个差异基因,其中320个上调基因,429个下调基因。
表3 TCGA验证差异基因
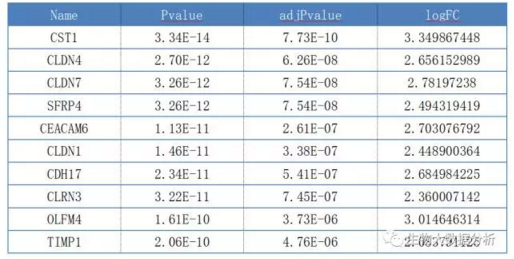
注:
Name gene symbol
logFC 每个实验差异logFC均值
Pvalue 统计学p值
adjPvalue 校正后的p值
四、生存分析
从TCGA下载生存数据,并将生存数据和差异基因表达数据整合在一起,做接下来的生存分析。使用survival R包进行生存分析并绘制生存曲线,统计检验为log rank检验,过滤条件为Pvalue<0.01。通过分析,共找到168个与胃癌生存相关的差异基因,结果保存在04_TCGAsurvival/survival.xlsx里面。168个生存相关基因的生存曲线保存在04_TCGAsurvival/picture目录下。
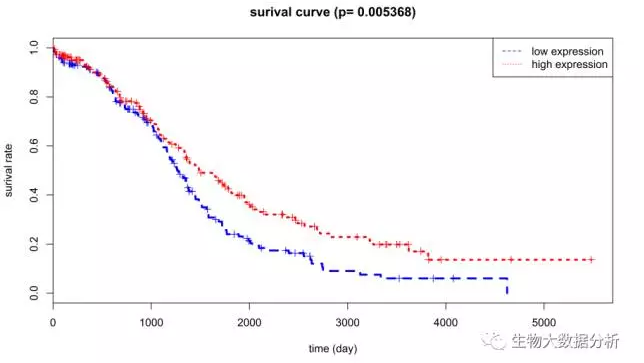
图2 生存分析
图中,横坐标是生存时间,纵坐标是总生存率,红色表达基因高表达组,蓝色代表低表达组。
五、GO富集分析
使用DAVID对目标靶基因进行GO功能富集分析,FDR<0.05被作为筛选条件,我们共找到5个相关的GO,(即“extracellular space”、“digestion”等),使用ggplot2 R包绘制GO富集柱状图。5个相关GO表格和GO富集柱状图保存在diffSig\GO\GO.xls目录下。
图5 GO富集结果
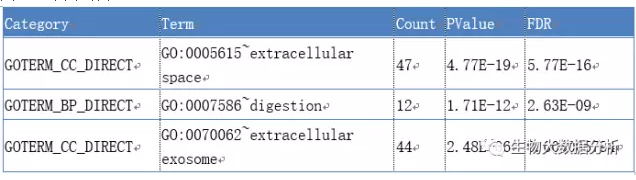
注:
Term 富集的GO
Count 差异基因落在Term的数目
PValue 富集统计学p值
FDR 统计FDR值(false discovery rate)
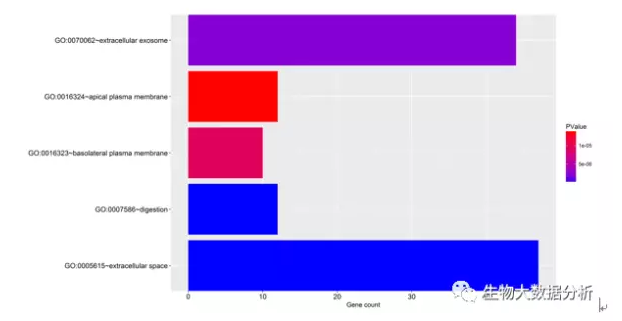
图3 GO富集柱状图
横坐标是富集在GO的基因数目,纵坐标是富集的GO。颜色代表富集的统计学显著性,越蓝表示富集程度越高。
六、KEGG富集分析
使用KOBAS对差异基因进行KEGG通路富集分析,CorrectedP-Value<0.05被作为筛选条件。我们共找到23个相关的KEGG,富集的表格保存在diffSig\KEGG\KEGG.xlsx目录下,最富集通路hsa04971图保存在diffSig\KEGG\hsa04971.png目录下。如果需要查看其它富集通路的通路图,可以打开差异diffSig\KEGG\KEGG.xlsx,点击相应通路的Hyperlink链接即可。
表6 KEGG富集结果
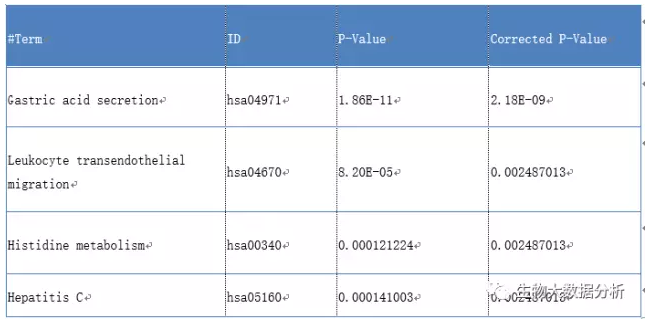
注:
Term 富集的KEGG
ID KEGG ID
P-Value 富集统计学p值
CorrectedP-Value 矫正后的p值
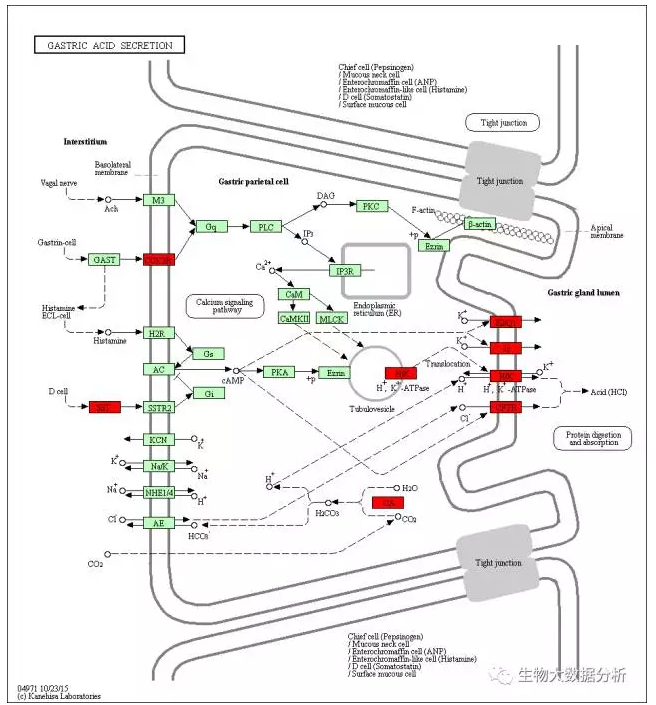
图4 hsa04971通路图
绿色代表通路中的基因,红色代表我们输入的生存相关基因。
七、蛋白互作网络
使用String软件对生存相关基因构建蛋白互作网络,得到蛋白的相互作用关系。图1是蛋白互作网络图,图中圆圈代表蛋白,连线蛋白蛋白之间存在互作关系。使用R软件绘制互作网络邻接节点数目图,图2是每个蛋白的邻接节点数目,邻接节点数目越多,说明该基因位于蛋白互作网络的核心,对整个网络起的作用最关键。由图2可以看出,CFTR、SST、TIMP1等位于网络的最核心。蛋白互作网络图和互作网络邻接节点数目图、互作网络邻接节点数表格保存在diffSig\蛋白互作网络目录下。
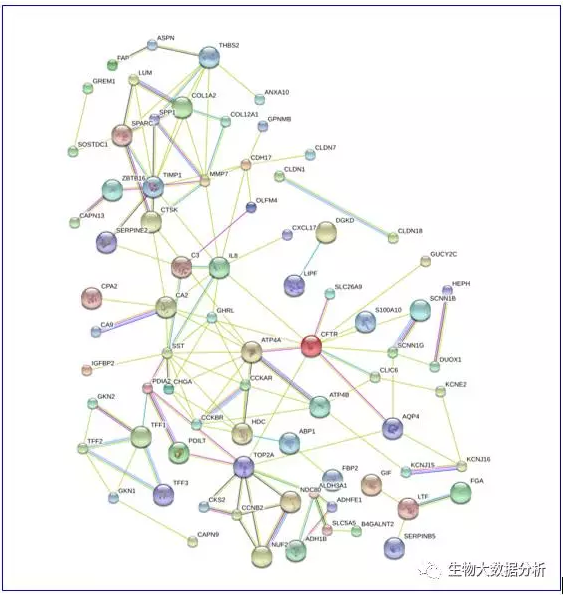
图5 蛋白相互作用网络图
圆圈代表基因,线条代表基因间存在蛋白相互作用,圆圈内部的结果代表蛋白的结构。线头颜色代表证明蛋白之间存在相互作用的不同证据。(small nodes:protein of unknown 3Dstructure; large nodes: some 3D structure is known or predicted; A red lineindicates the presence of fusion evidence ; a green line - neighborhoodevidence; a blue line - coocurrence evidence; a purple line - experimentalevidence; a yellow line – text mining evidence; a light blue line -database evidence; a black line - coexpression evidence.)
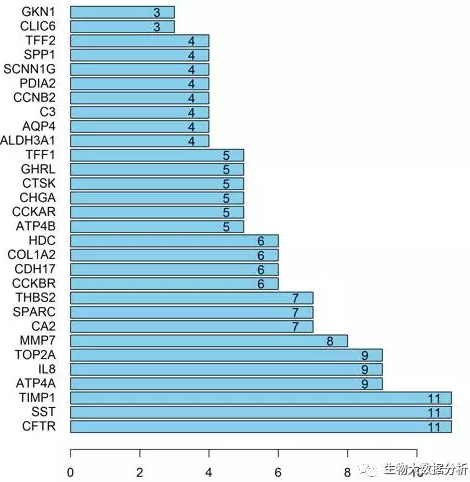
图6 互作网络邻接节点数目
横坐标是基因的邻接节点数目,纵坐标是基因名称。

责任编辑:伏泽
作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载!
|




