差异分析及id转化1、差异分析首先我们看一下差异分析的过程,如下图,本来我们这里的样品是随机打乱的,然后根据我们的目标基因,我们可以对这里的样品进行整理,把我们目标基因低表达的样品放前面,高表达的样品放后面,得到一个新的矩阵。得到新的矩阵之后,我们就可以对这个新的矩阵进行差异分析。 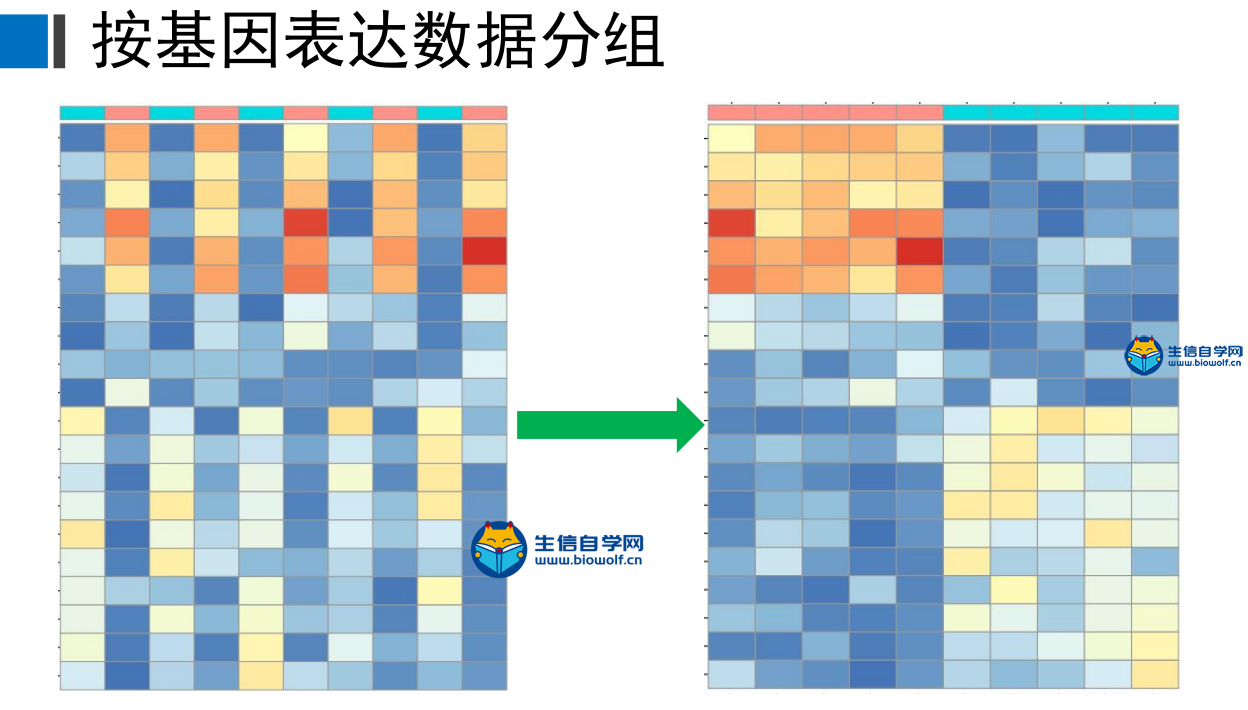 进过差异分析,我们可以得到这样一个表格,这个表格第一列是基因的名称。第二列是logFC值,第三列的是这个基因在所有样品里面的均值,接下来就是检验值,就是高表达组和低表达组差异的一个检验值。根据检验值,我们就可以得到P值。同时我们对P值进行校正,得到矫正后的P值。我们在筛选的时候,一般是根据logFC的绝对值大于1,然后矫正后的P值小于0.05进行筛选。但是我们在做分析的时候经常会碰到这样的情况,就是我们按照这个标准筛选出来的结果可能得不到任何基因。我们就可以把这个logFC的绝对值放宽,把它放宽到0.5。当然可能我们选择某个基因的时候,我们的这个差异基因特别多,比如说有几千,这个时候我们也要考虑把这个logFC的绝对值把它放严格一点,比如说把它放到2,这样的话我们就可以得到差异分析的结果。 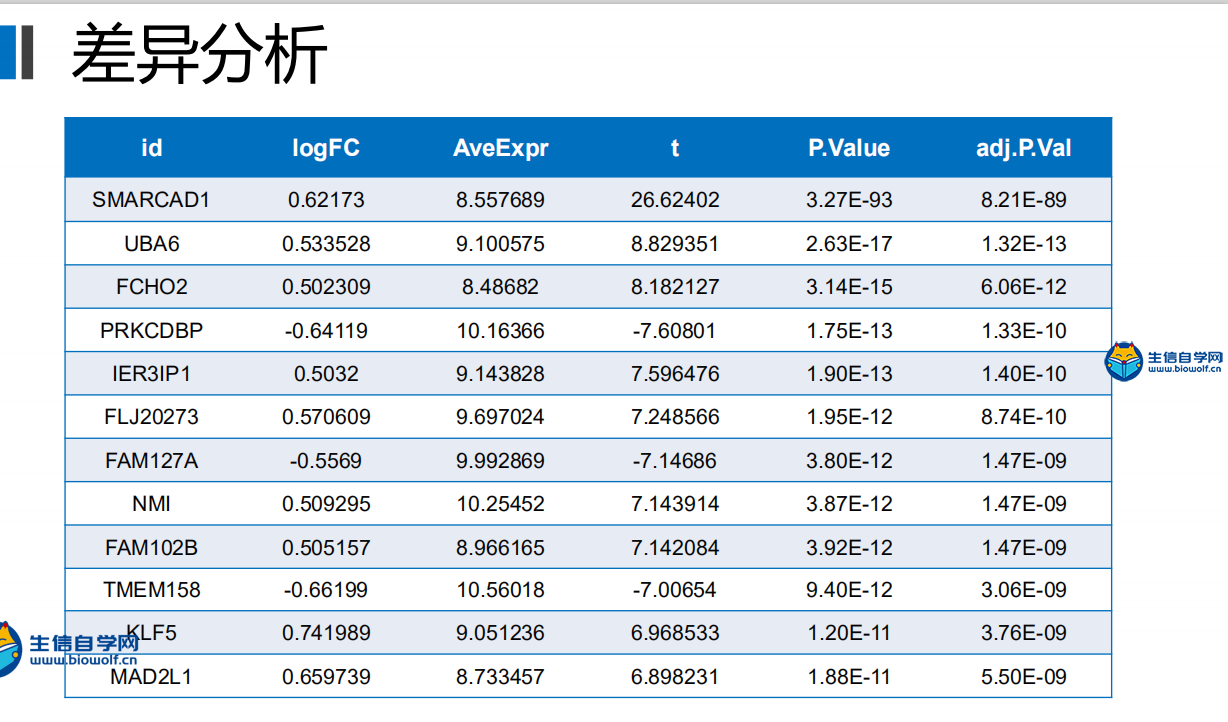 接下来我们看一下差异分析的脚本和输入文件,输入文件的话就是我们所有基因在所有样品里面的表达量normalize.txt。  准备好输入文件后,将脚本文件复制粘贴到R中运行,等待运行结束,我们就可以得到几个输出文件,分别是所有基因的差异情况文件all.xls,满足条件的差异基因文件diff.xls,共表达的输入文件corInput.txt,热图和火山图,还有一个diff.txt文件,用作id的转化。 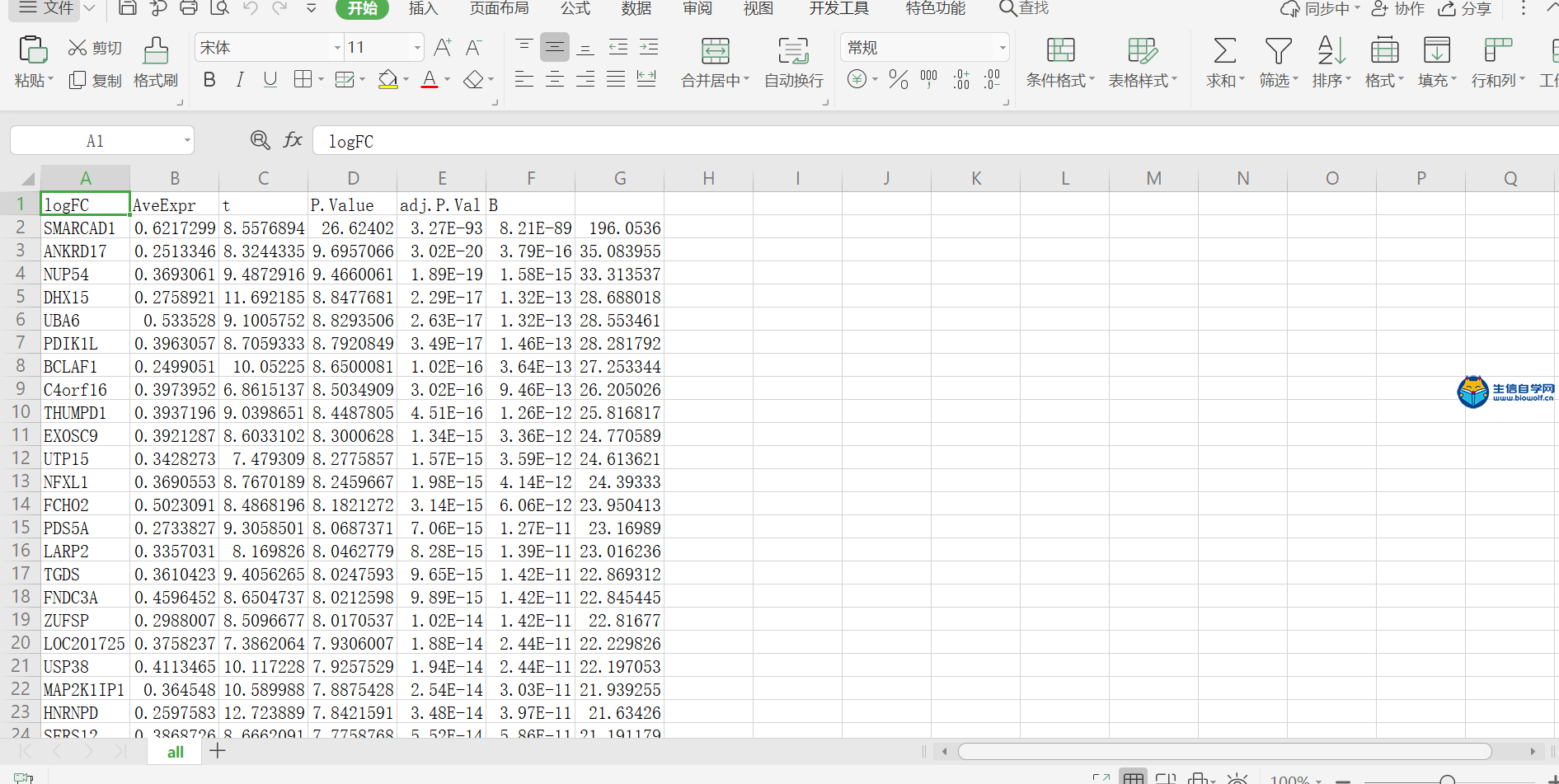 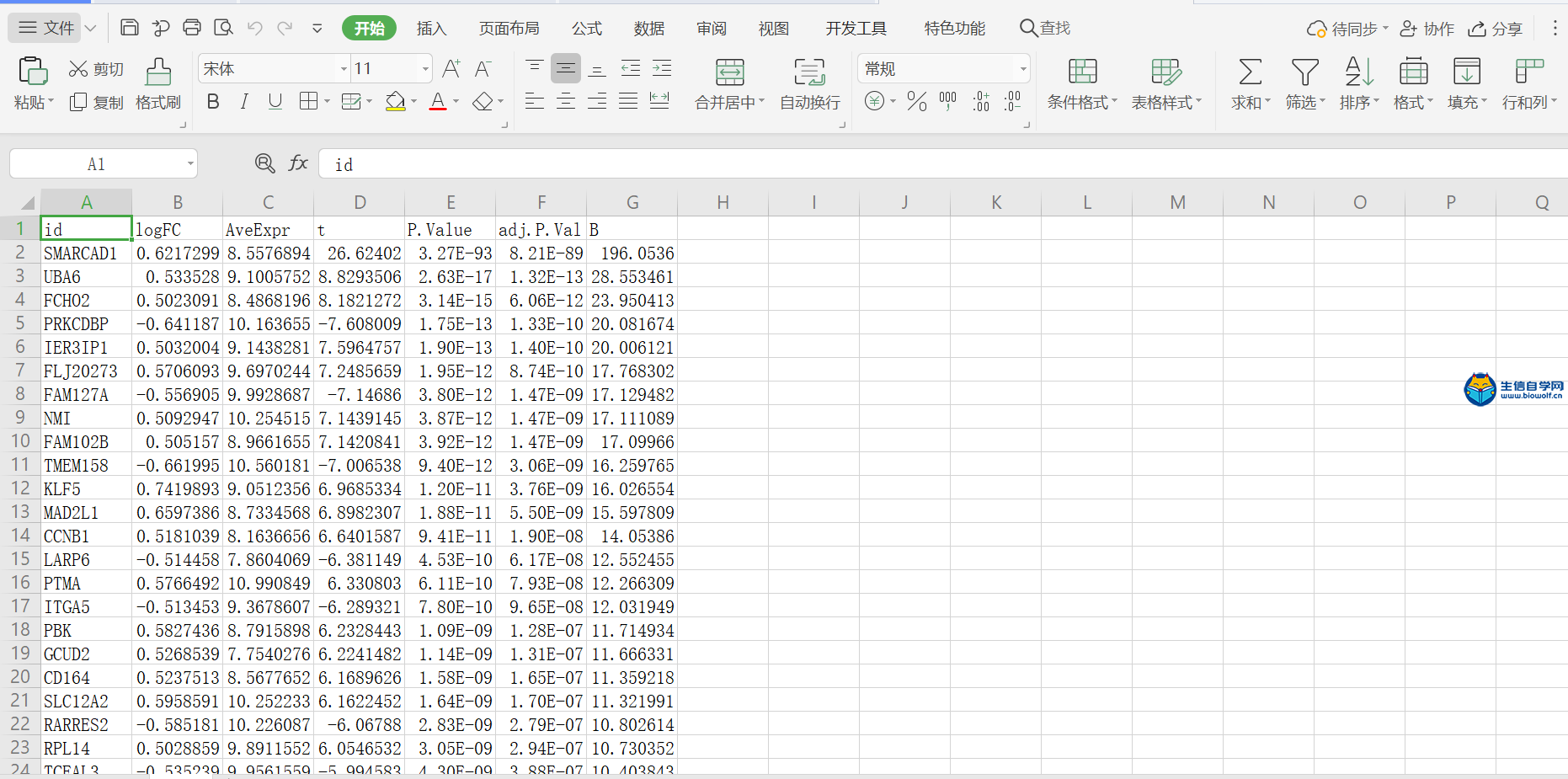  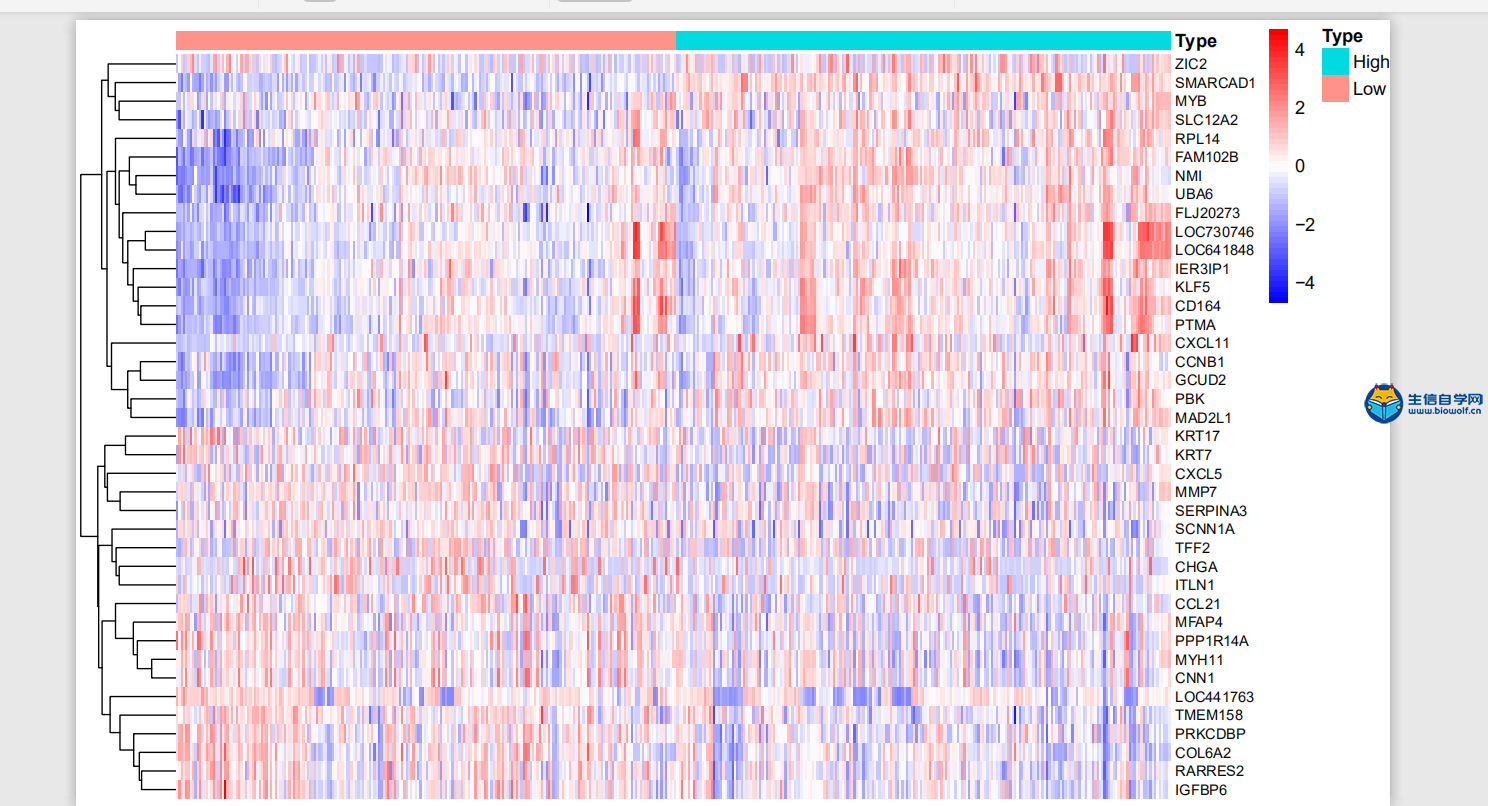 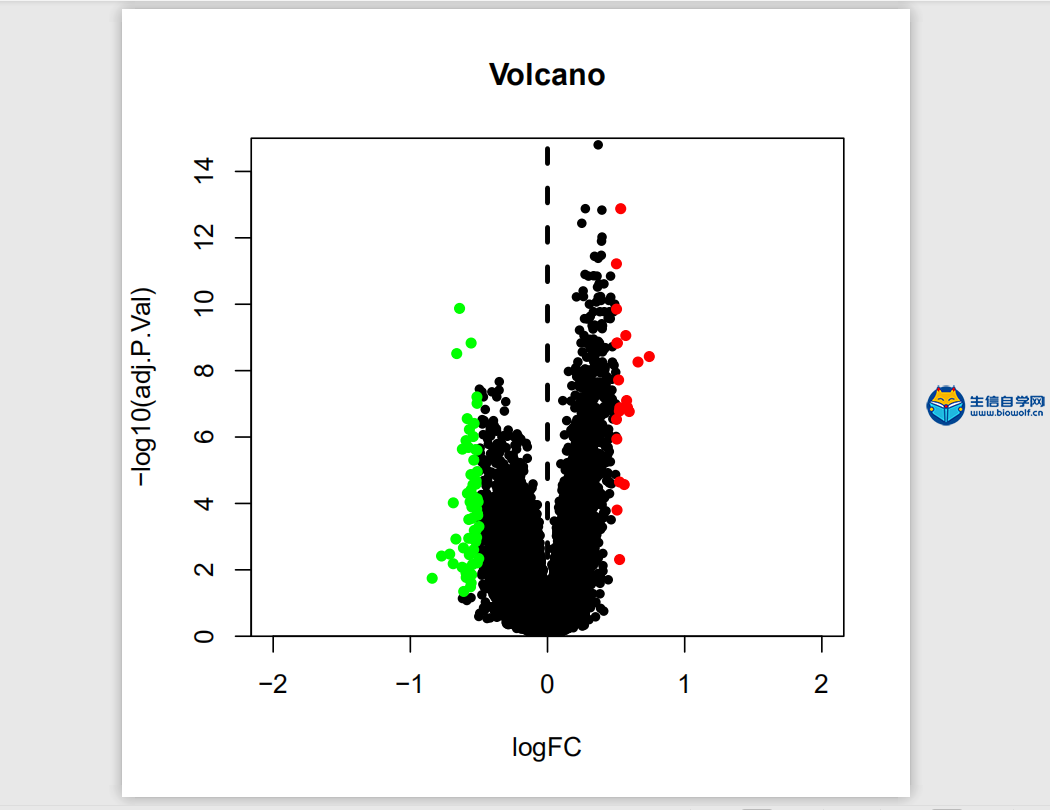 2、id转化 得到差异基因之后,接下来我们就可以做GO和KEGG的富集分析。看我们的目标基因是通过调节什么样的通路和什么样的功能来影响我们肿瘤的发生。因为我们这里做GO和KEGG富集分析,我们使用的是R包完成的,使用R包的话需要我们输入基因的id。而我们做完了差异分析之后,只得到基因的名字,所以我们要做GO和KEGG富集分析之前。我们就需要将我们基因的名字转化为基因的id。下面我们看一下转换的过程,首先我们有个这样的表格,这个表的话有两列信息,第一列就是我们基因的名字,然后第二列就是logFC。然后我们就要把这个表格里面的基因的名字转化为基因的id,也就是说在我们这个表格的基础上把基因的id加在我们的表格的后面。 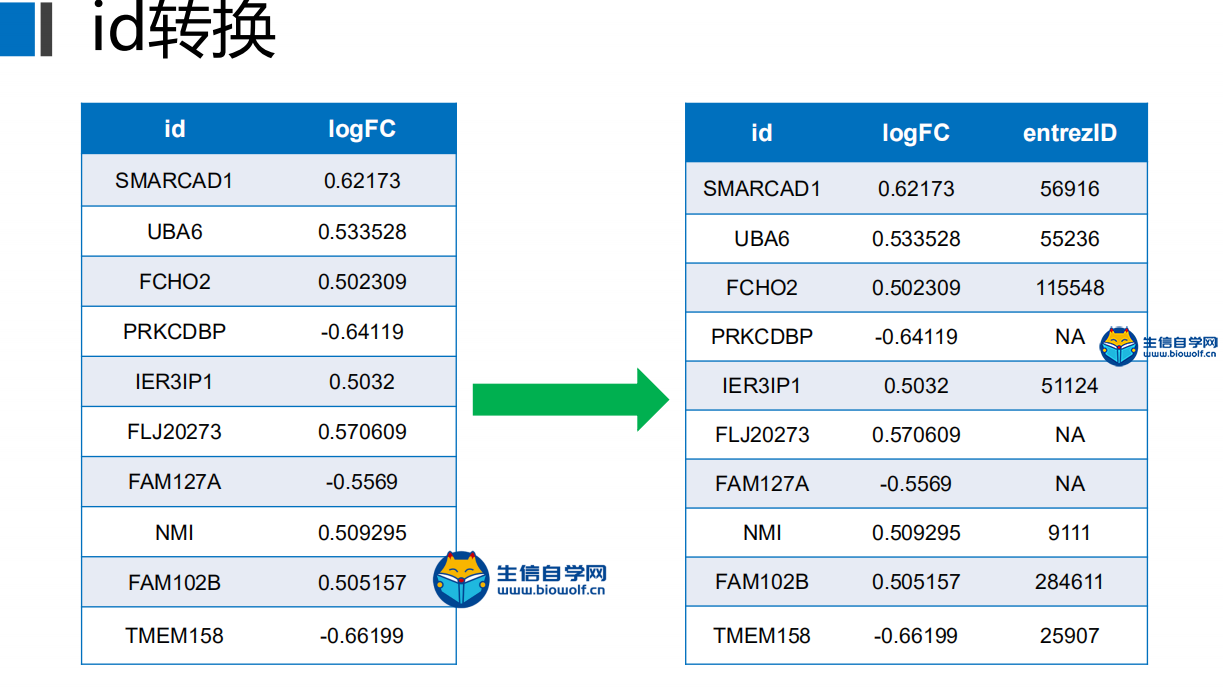 我们需要的输入文件,输入文件就是我们刚刚得到的diff.txt文件。 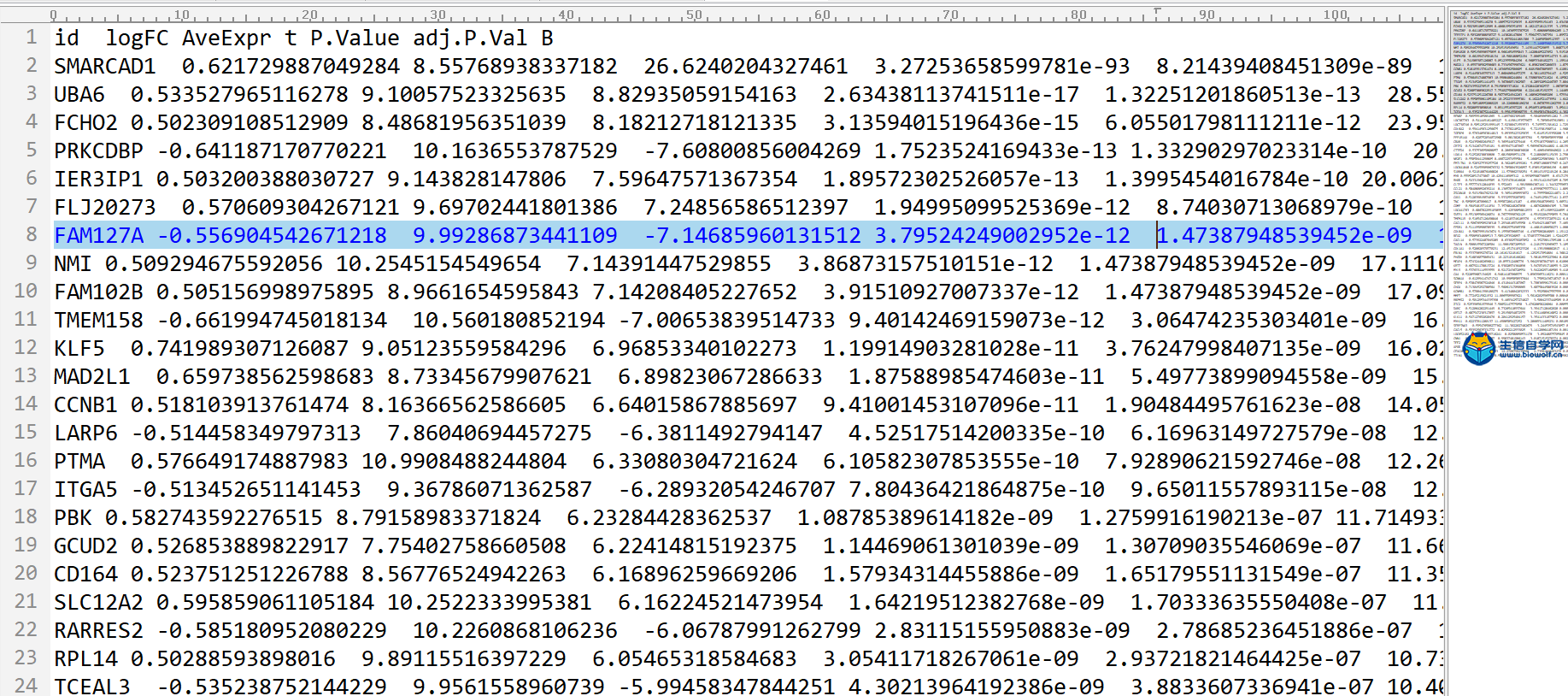 运行脚本文件,我们就可以得到转化后的文件。 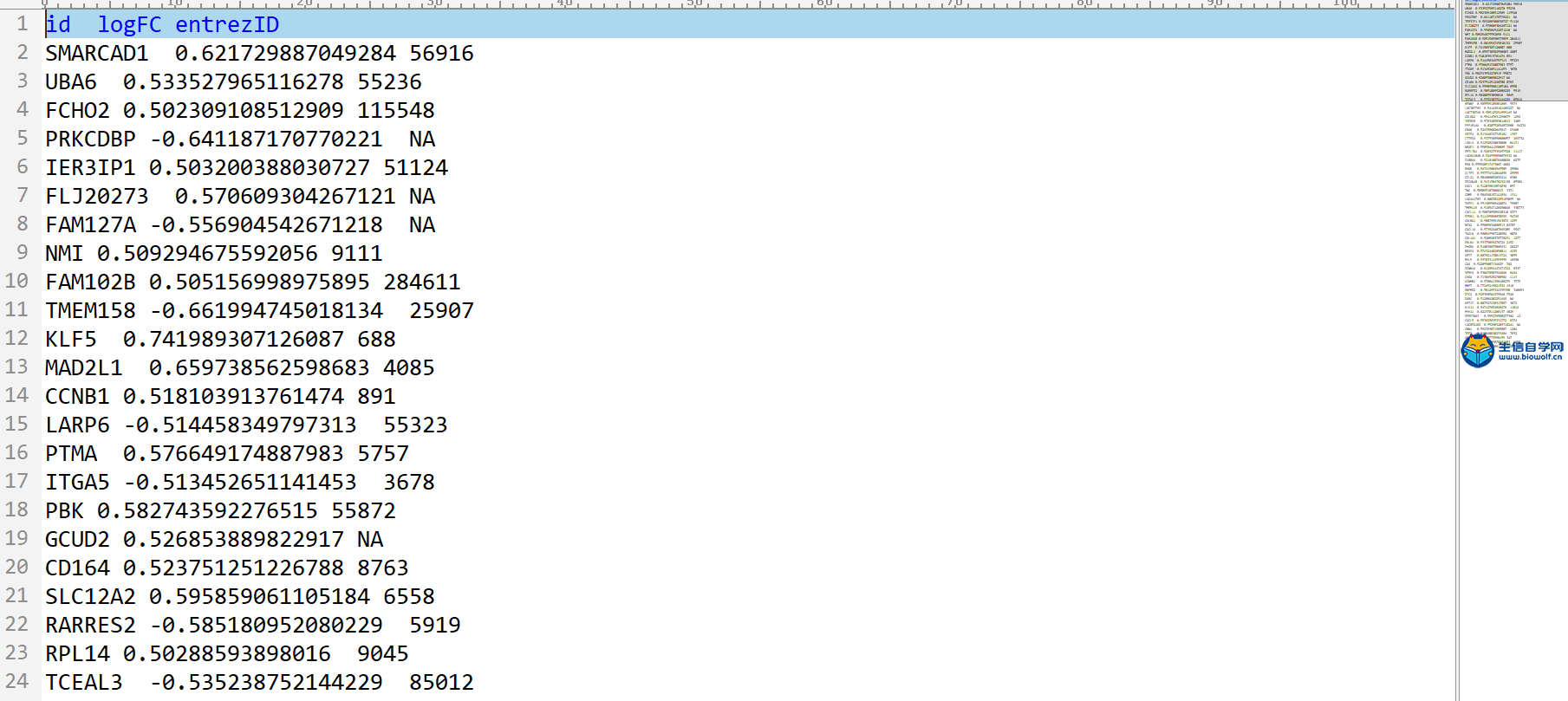 精品课程推荐: 《GEO基础课程》 《GEO数据库单基因挖掘文章套路》 《GEO数据库单细胞测序》  
责任编辑:伏泽 作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载! |




