|
基因怎么有那么多种类的ID?这个问题着实困扰着很多初学者,就算是有多年GEO、TCGA数据库分析经验的大牛也会被这些问题迷惑,有时候数据下载下来,满心欢喜本以为马上可以得到差异基因,去做后续分析了,打开文件一看眼睛大了,怎么和平时的基因不同,这黑乎乎一大串是个什么东东。 生物数据量之大,大到电脑卡机,一个上G的文本文件,不要轻易用excel去打开,否则你会很伤心的看着电脑屏幕发呆。前人也许没有预料到生物分子学会发展如此迅速,基因数目会如此庞大,最终还是把命名这个问题给搞复杂了,随着生物数据库越来越多,做大做强的数据库开始拥有自己的一套基因命名规则,于是乎,就变成了几大ID共同存在的大杂烩局面。 我们首先来认识一下Ensembl Gene ID,Ensembl Gene ID的命名比较长,也是后起之秀,使用比较广泛,就是这么一串字符:ENSG00000279964,我们可以到ensembl的在线工具直接搜索这个ID,得到的是“Gene: AC009949.1 ENSG00000279964”,解释是这样的:“No overlapping RefSeq annotation found”,很显然这是一个lncRNA也就是非编码的RNA。那么我们就可以看到ENSG00000279964对应的gene symbol ID就是AC009949.1。  gene symbol ID是使用最早,使用最广泛的ID形式 ,一般我们做差异都是要用symbol的矩阵来做,大部分miRNA靶基因预测网站得到的miRNA靶基因也是用symbol ID。可以说,不管数据记录时用的是什么ID,最后出结果,写报告,发表论文,都是公认symbol ID的,所以在看到我们下载的矩阵不是Gene Symbol ID时,我们就要想办法转换成symbol ID。 如果是单个,少量的Ensembl Gene ID需要转换成gene symbol ID,那么直接在ensembl网站一个一个去检索就可以得到结果。然而现实却不是如此的,一个矩阵下来就是4万行,这个数量级的ID要检索,手工当然不现实,当然不服气的可以去试试。 乔帮主说过“编程可以让一个人变得睿智”,这个观点不知道是否正确,但处理生物信息时,脚本给我们带来了福音,只需要把后台数据库下载下来,跑下脚本就可以得到结果。看着输出的结果,就会感到,学习还是有点用啊,至少不要花半年时间去检索。 回到问题本身,需要先到ensembl网站下载相关物种的ID文件,点击“Download”,进入下载页面,点击右边的Download data via FTP,进入FTP下载页面。  进到FTP页面,这里需要选择物种,例如做人,就选择Human后面的GTF文件,进到下载页面,直接下载Homo_sapiens.GRCh38.89.chr.gtf.gz这个文件,这个文件是30多M,解压之后是1个G,有一次感觉生物数据库的庞大。  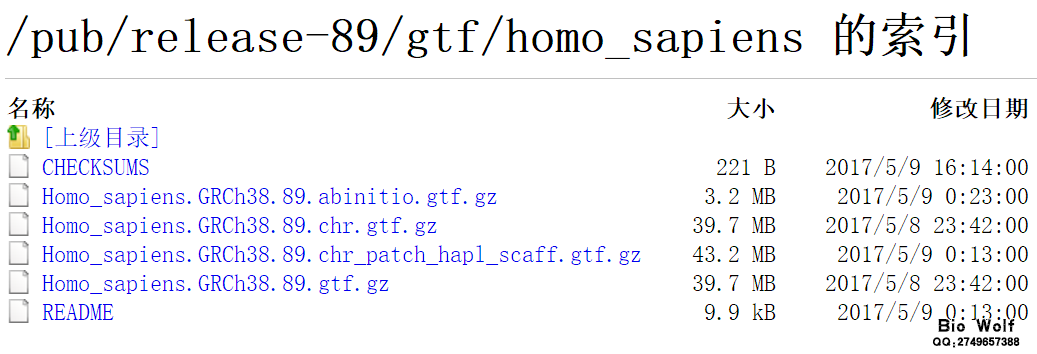 做好准备工作,就要运行脚本了,在CMD环境下输入命令:perl getsymbol.pl Homo_sapiens.GRCh38.89.chr.gtf.gz sample.txt symbol.txt ,输入命令之后潇洒的按下回车键,就可以放松一下神经,等win10慢慢去跑,当然这个过程也很快,如果还是学习机,那时间就不确定了,等待是漫长的,时间是宝贵的,装备不行的赶紧升级。生物信息的处理,没有一个好机子,寸步难行。 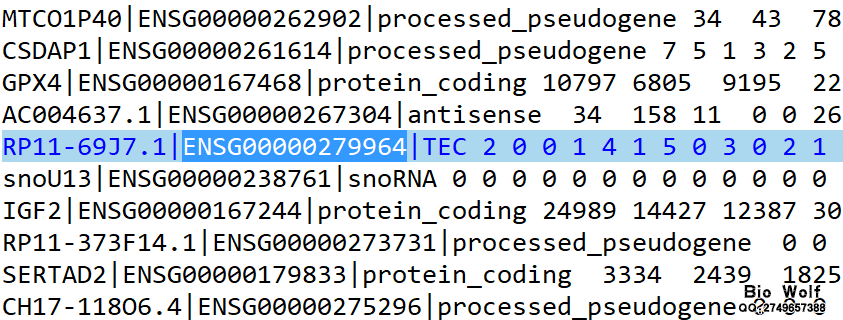 
责任编辑:伏泽 作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载! |




