GO与KEGG的富集分析1、GO富集分析我们已经将基因的名字转化为了id,接下来我们就可以做GO的富集分析。通过GO富集分析,我们可以得到柱状图和气泡图,我们这里就讲解一下气泡图,它的纵坐标就是我们GO的名称,然后横坐标就是基因的比例,这个圆圈的大小就代表富集在每个GO上基因的一个数目,圆圈越大就代表在这个GO上,富集基因的数目越多,然后这个圆圈的颜色就代表富集的显著性。这个圆圈越红就说明我们的差异基因在这个GO上富集越显著,所以我们在看这个图的时候,我们就选择圆圈比较红的这些GO去做重点讨论。 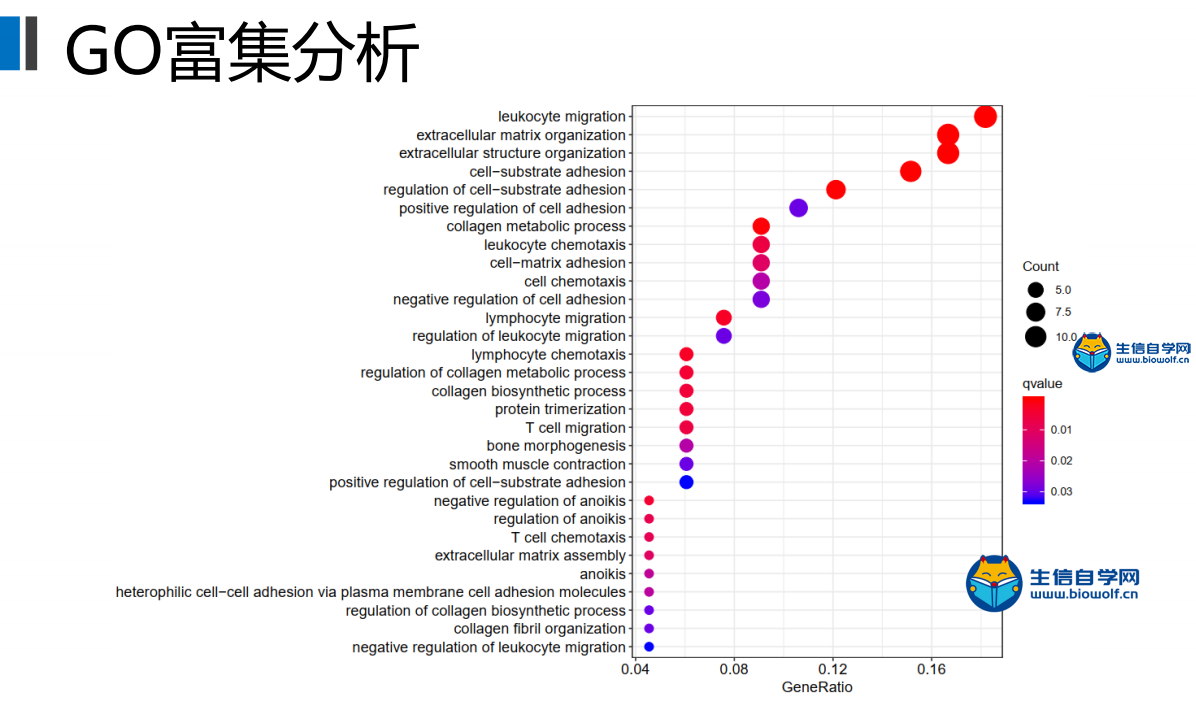 下面我们准备GO富集分析的脚本文件和输入文件,输入文件我们需要id转化后的文件。脚本文件由生信自学网提供,有需要的学员可以通过下方的链接和联系方式购买我们的视频进行学习。  运行完脚本文件后,我们就可以得到我们的柱状图和气泡图,还有进行富集分析后的结果文件。 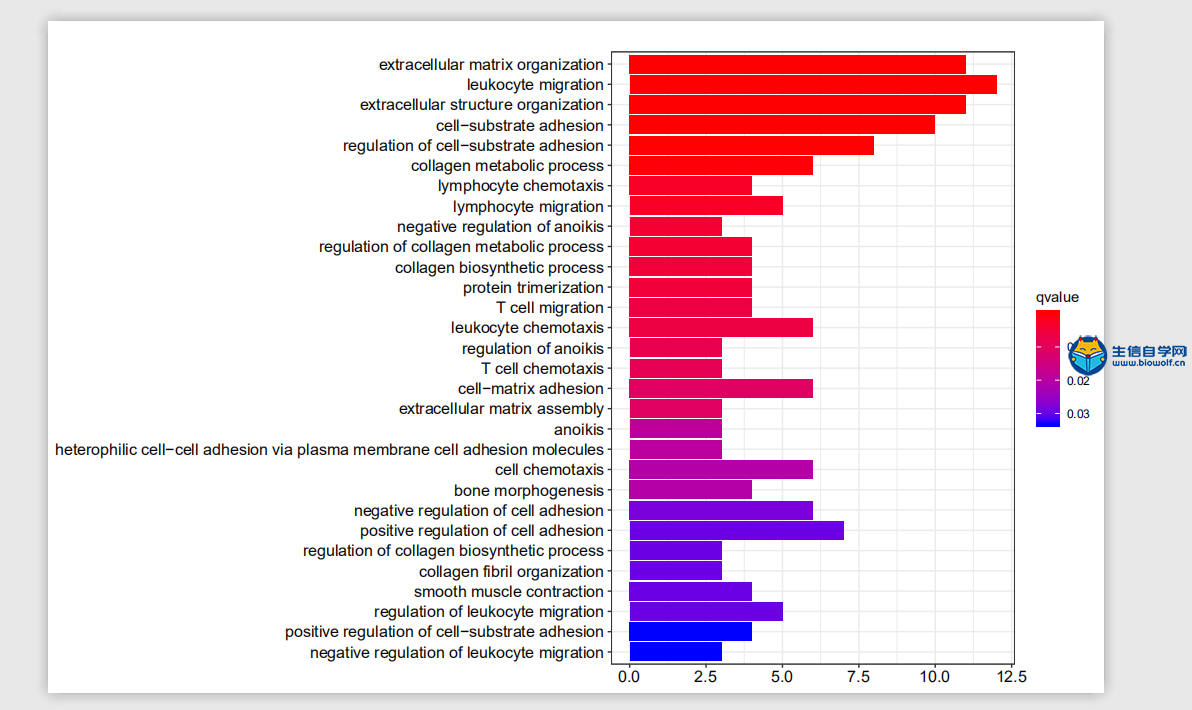 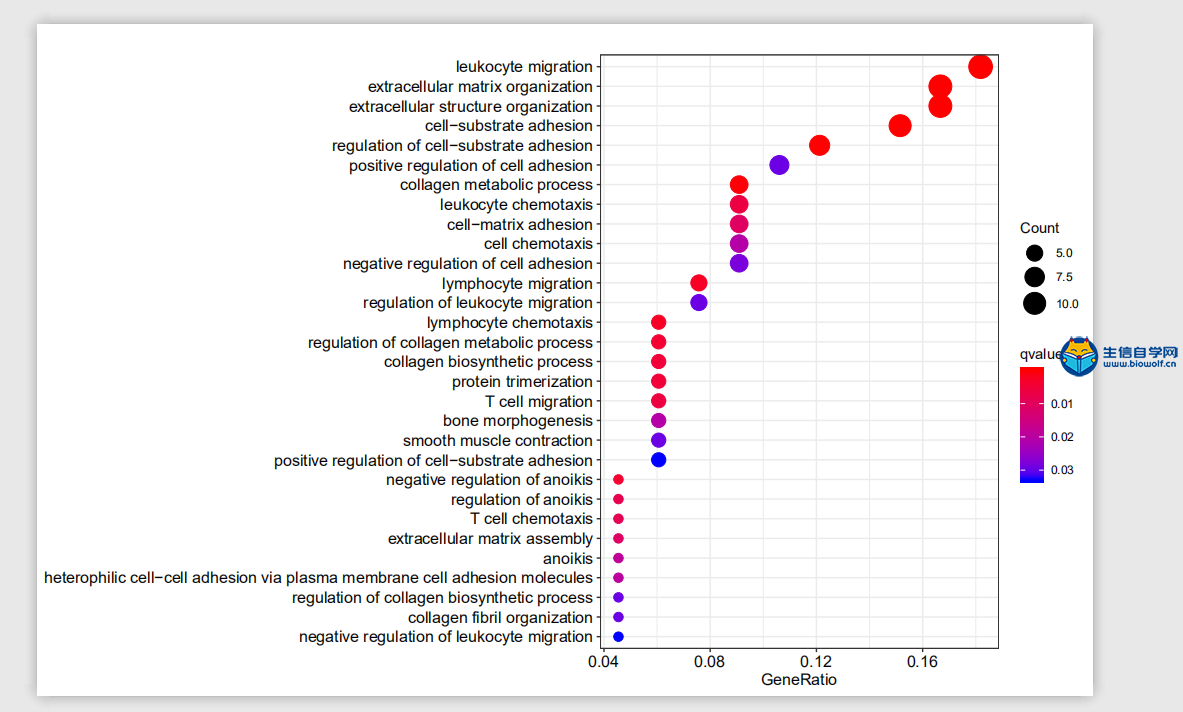  2、KEGG富集分析 接下来我们进行KEGG富集分析,富集分析之后,我们也可以得到柱状图和气泡图,同样我们重点会看一下这个气泡图,它的纵坐标就是通路的名称,然后横坐标的话就是基因的比例。那这个圆圈的大小就代表富集在每个通路上基因的数目,圆圈越大的话,就表示富集在这个通路上,基因的数目越多。这个圆圈的颜色就代表富集的显著性,圆圈越红就代表我们的差异基因,在这个通路上富集越显著。 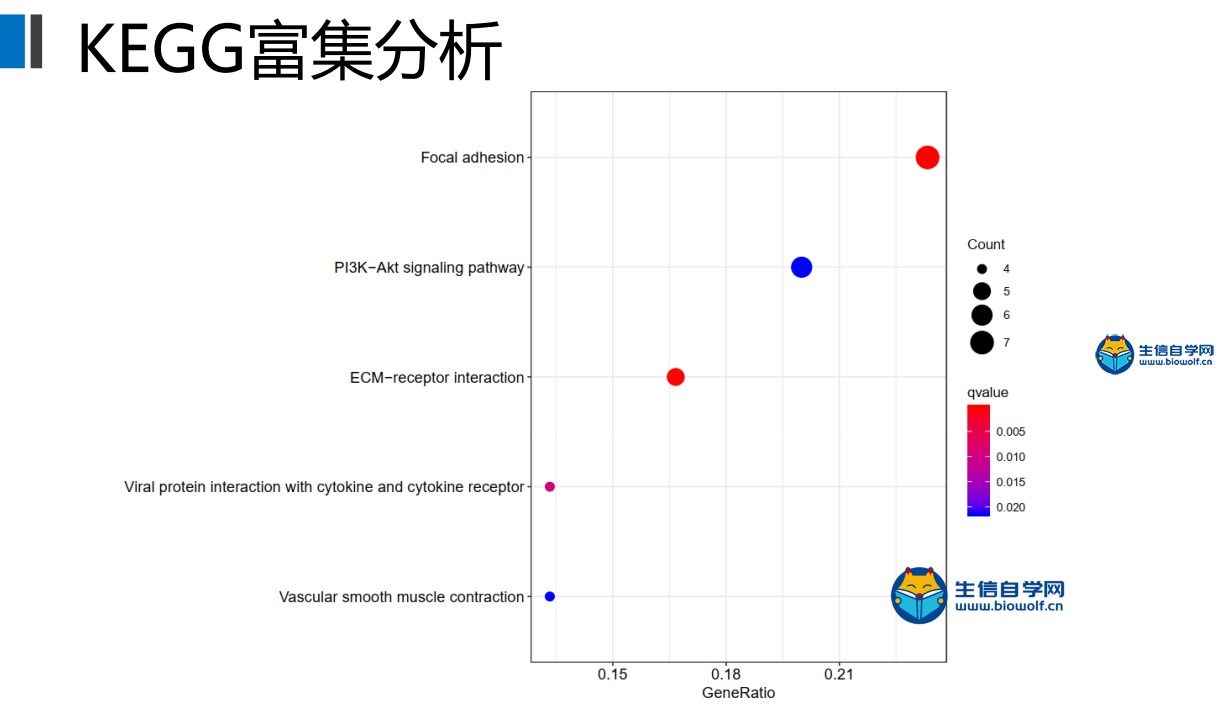 输入文件的话同样是id转化后的文件,脚本文件由生信自学网提供。用R运行准备好的脚本文件,运行完成后,我们同样可以得到我们的柱状图和气泡图,和KEGG富集分析后的结果文件。 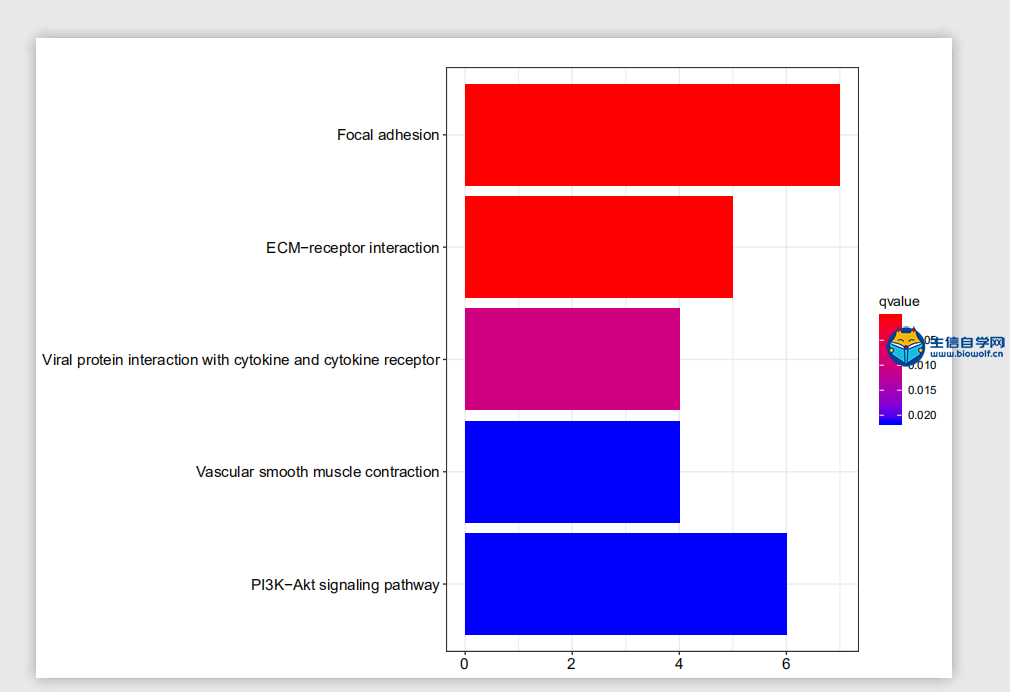 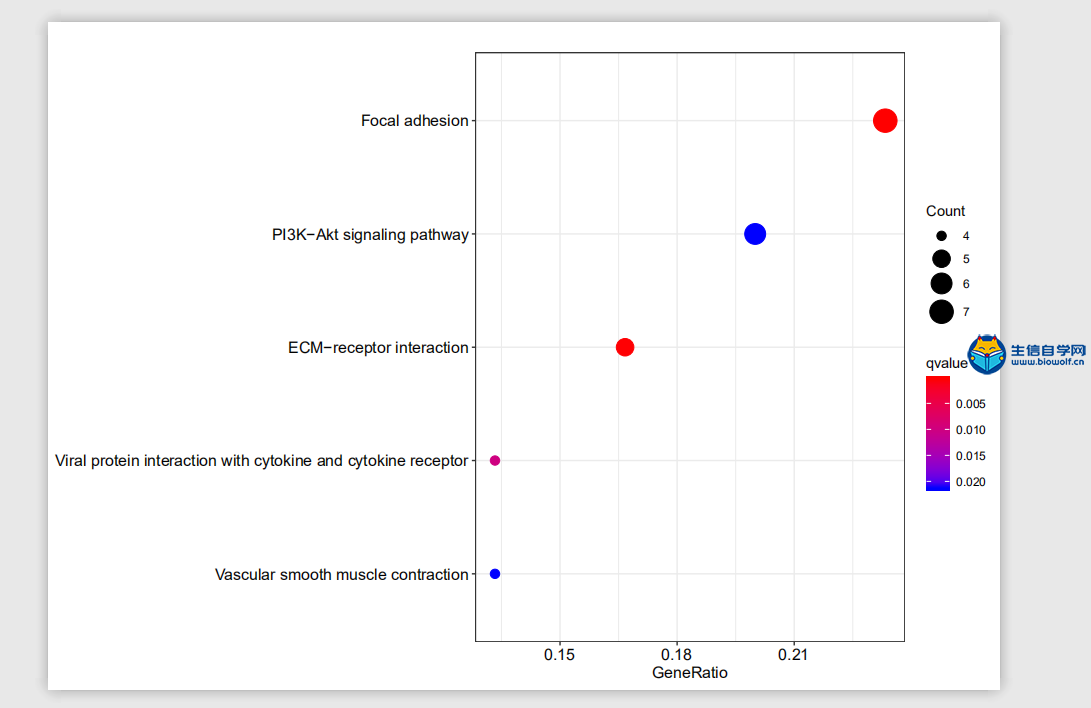 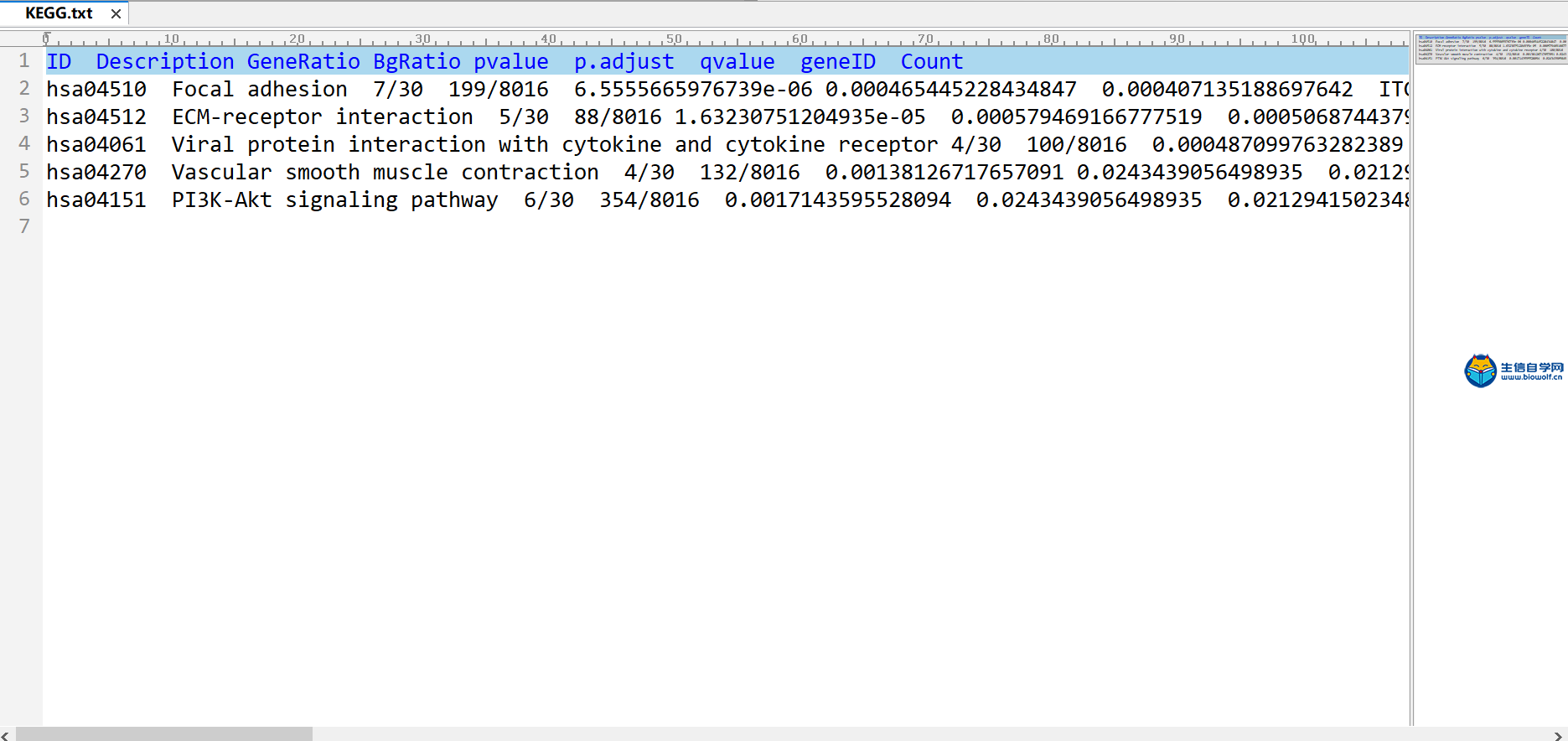 精品课程推荐: 《GEO基础课程》 《GEO数据库单基因挖掘文章套路》 《GEO数据库单细胞测序》  
责任编辑:伏泽 作者申明:本文版权属于生信自学网(微信号:18520221056)未经授权,一律禁止转载! |




